Masked Autoencoders Are Scalable Vision Learners
Highlight
- Masked Auto-Encoder is a very simple self-supervised training approach that gives state-of-the-art results
- Asymmetric encoder-decoder architecture that reduce the computation cost
- Does not rely too much on data augmentation : only crops are used
Method
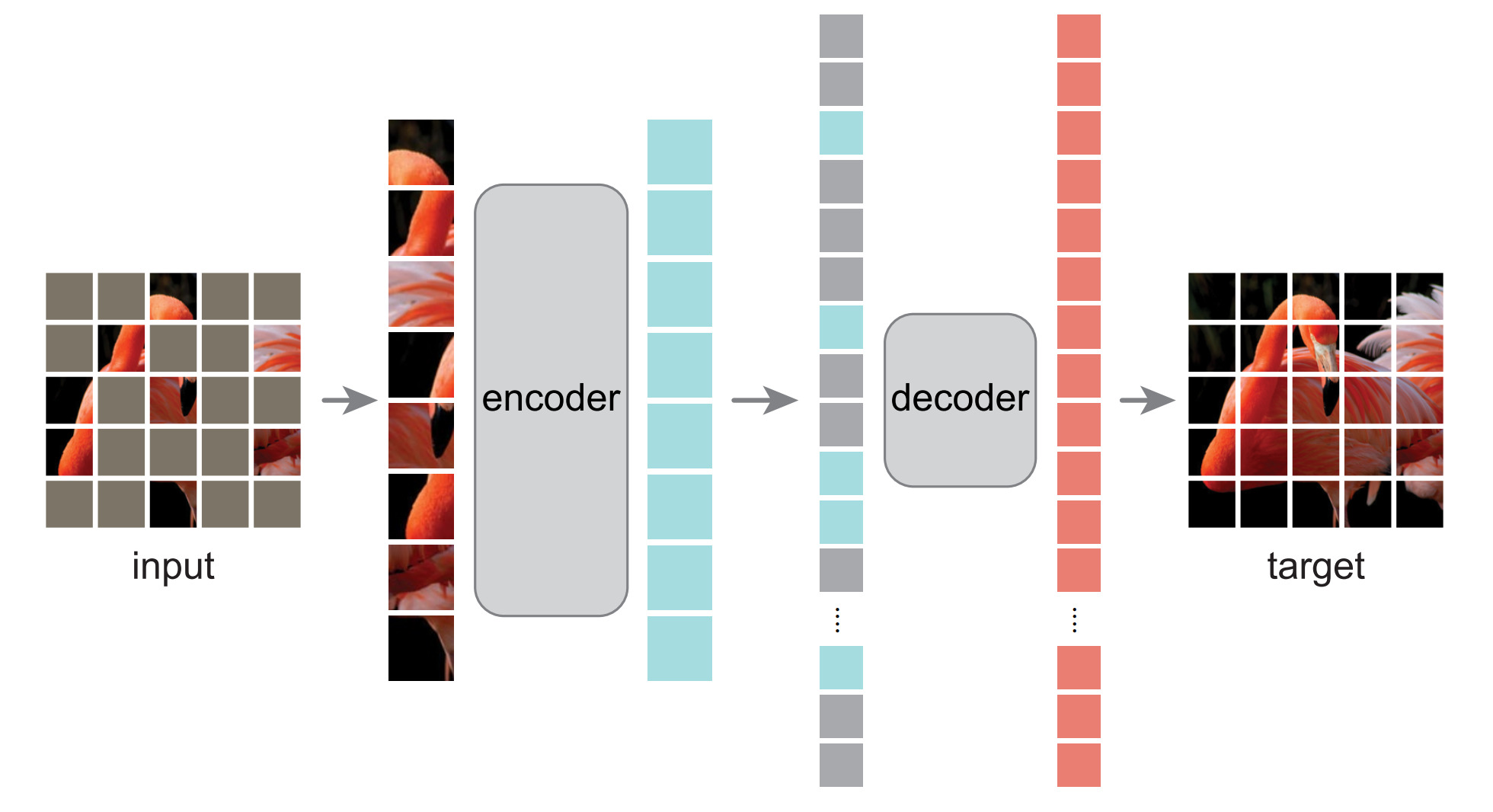
Masking
The image is split into patches as in the original ViT, then 75% of the patches are masked (removed) following a uniform distribution
Encoder
It uses the ViT architecture and only take in input the tokens of visible patches
Decoder
- It also uses the ViT architecture, but is smaller than the encoder
- Masked token are added to the sequence before being fed to the decoder
- The final layer of the decoder is a linear layer that predicts pixel values for each token
- The masked token are shared and learned during the training
Loss
- The loss is the MSE between the groundtruth pixel values and the predicted pixel values
- The loss is only computed on the masked tokens !
- However, the authors report that the accuracy drop only slightly if the loss is computed on all tokens
Experiment
- Dataset : ImageNet-1K
- Model :
- Encoder : ViT-Large (24 blocks, width of 1024)
- Decoder : 8 blocks with a width of 512
- Training time : 16 hours for 800 epochs, using 128 TPU-v3 cores. (but it is faster than the other methods)
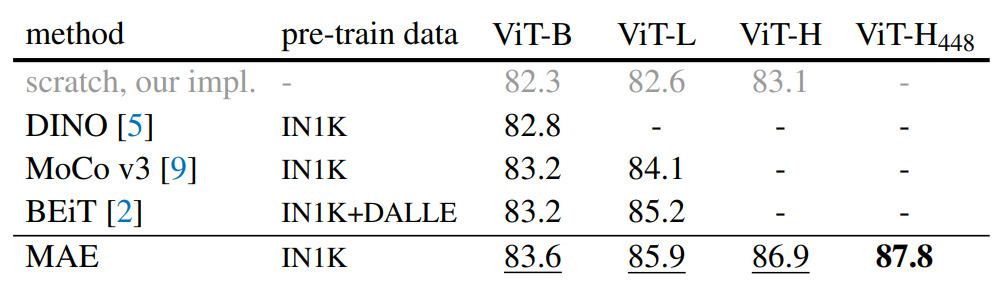
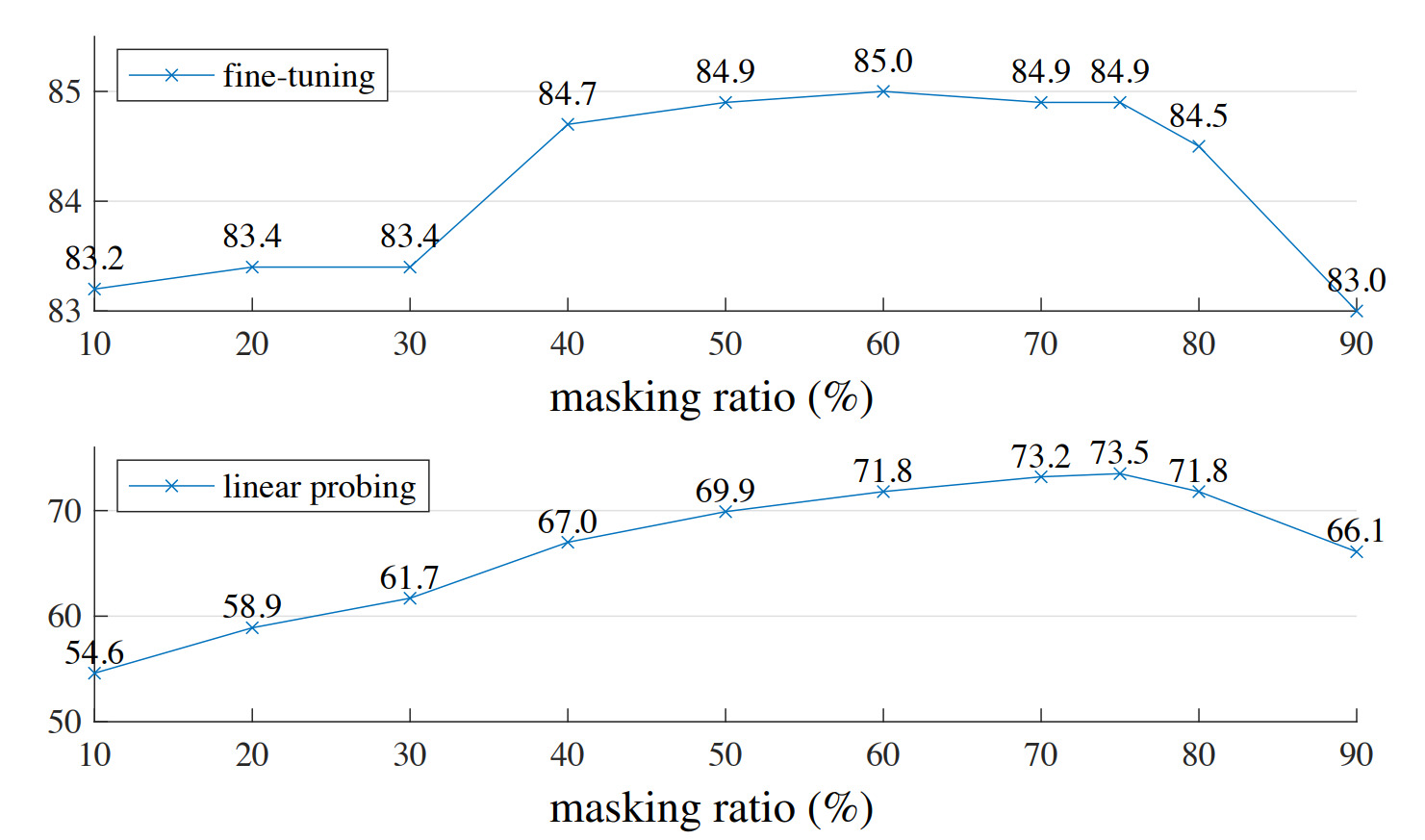
Results
Masking ratio
They find an optimal masking ratio of 75%
Examples from the validation set

Increasing the masking ratio
Note : the masking ratio was increased at inference time, the model was still trained with a masking ratio of 75%

Accuracy
First they do self-supervied pre-training and then a finetuning, the top-1 validation accuracy is reported below :
\[\begin{array}{ccc} \text { scratch, original } & \text { scratch, our impl. } & \text { baseline MAE } \\ \hline 76.5\% & 82.5\% & 84.9\% \end{array}\]Comparison with the state of the art