Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Useful links
Highlights
- ViT has a quadratic complexity with respect to the number of tokens ( and therefore image size). This makes ViT unsuitable for dense prediction task requiring a huge number of tokens such as segmentation.
- In the proposed architecture the Multi-Head Self Attention block (MSA) is replaced by a module based on shifted windows (W-MSA) which allow to obtain a linear complexity with respect to the number of token.
- In the ViT architecture, the size of the token matrix is constant throughout the network, whereas in the proposed architecture the number of token is reduced thanks to the patch merging layers. This operation allows building a hierarchical representation.
Architecture
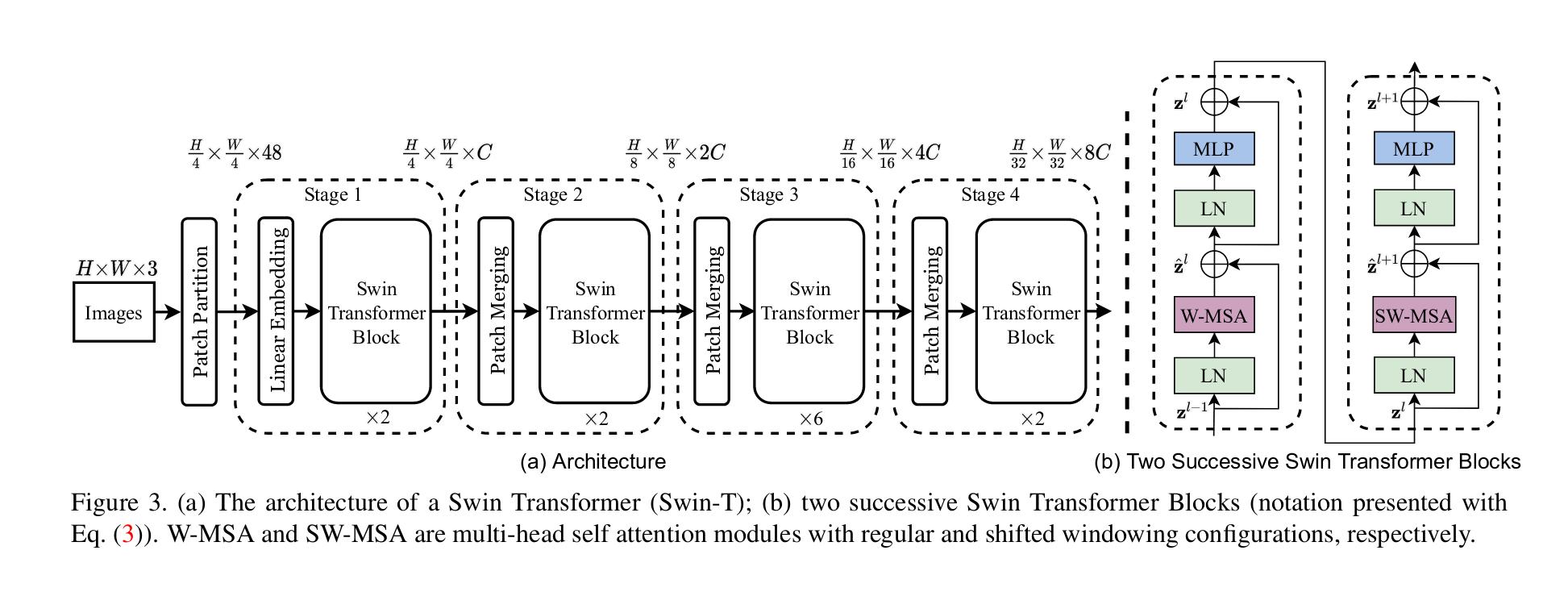
-
First the image of size \(H*W\) is split in \(N\) patches of size 4 x 4 to create tokens of size \(4*4*3=48\)
ViT have bigger patches of size 16 x 16 ( so less suitable for dense prediction task such as segmentation)
-
Then a linear embedding layer is applied to project it to an arbitrary dimensions \(C\)
-
Two Swin Transfomer blocks (with modified self-attention) are applied, resulting in a new matrix \(\mathbf{z} \in \mathbb{R}^{N \times C}\)
-
To produce a hierarchical representation, the number of tokens is reduced by patch merging layers as the network gets deeper
-
First, features of each group of 2 x 2 neighboring patches are concatenates giving a matrix \(\mathbf{z} \in \mathbb{R}^{\frac{N}{4} \times 4C}\)
-
A linear layer is applied to set the dimension of tokens to 2C and Swin Transformers blocks are applied
-
This first block of patch merging is referred as Stage 2
-
This process is repeated in Stage 3 ans Stage 4 to obtain a final matrix \(\mathbf{z} \in \mathbb{R}^{\frac{N}{64} \times 8C}\)
These steps produce a hierarchical representation similar to a convolutional networks. Therefore Swin Transformers can serve as a general backbone for several vision tasks.
Shifted Window based Self-Attention
-
Swin Transformer block is built by replacing the standard multi-head self attention (MSA) module in a Transformer block by a module based on shifted windows
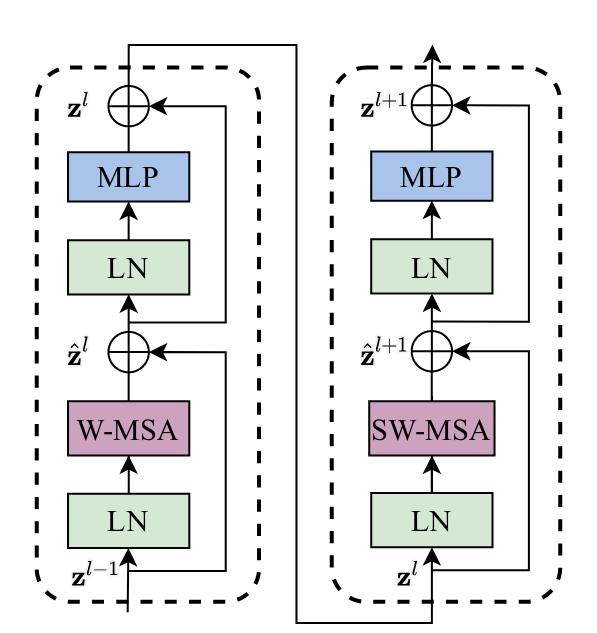
In this figure LN stands for Layer Normalization
-
The self-attention is computed within local windows. The windows are arranged to evenly partition the image in a non-overlapping manner.
-
For windows of size M x M patches and an image of h x w patches, the computational complexity of a standard MSA module and a window based self-attention module (W-MSA) are :
\[\Omega(MSA) = 4hwC^{2} + 2 (hw)^{2}C\] \[\Omega(W-MSA) = 4hwC^{2} + 2 M^{2}hwC\]Standard self-attention is quadratic to patch number \(hw\) whereas window based self-attention is linear when M is fixed
-
The W-MSA module lacks connections across windows. To overcome this problem windows are shifted alternatively between two different partitioning configuration in consecutive Swin Transformer block
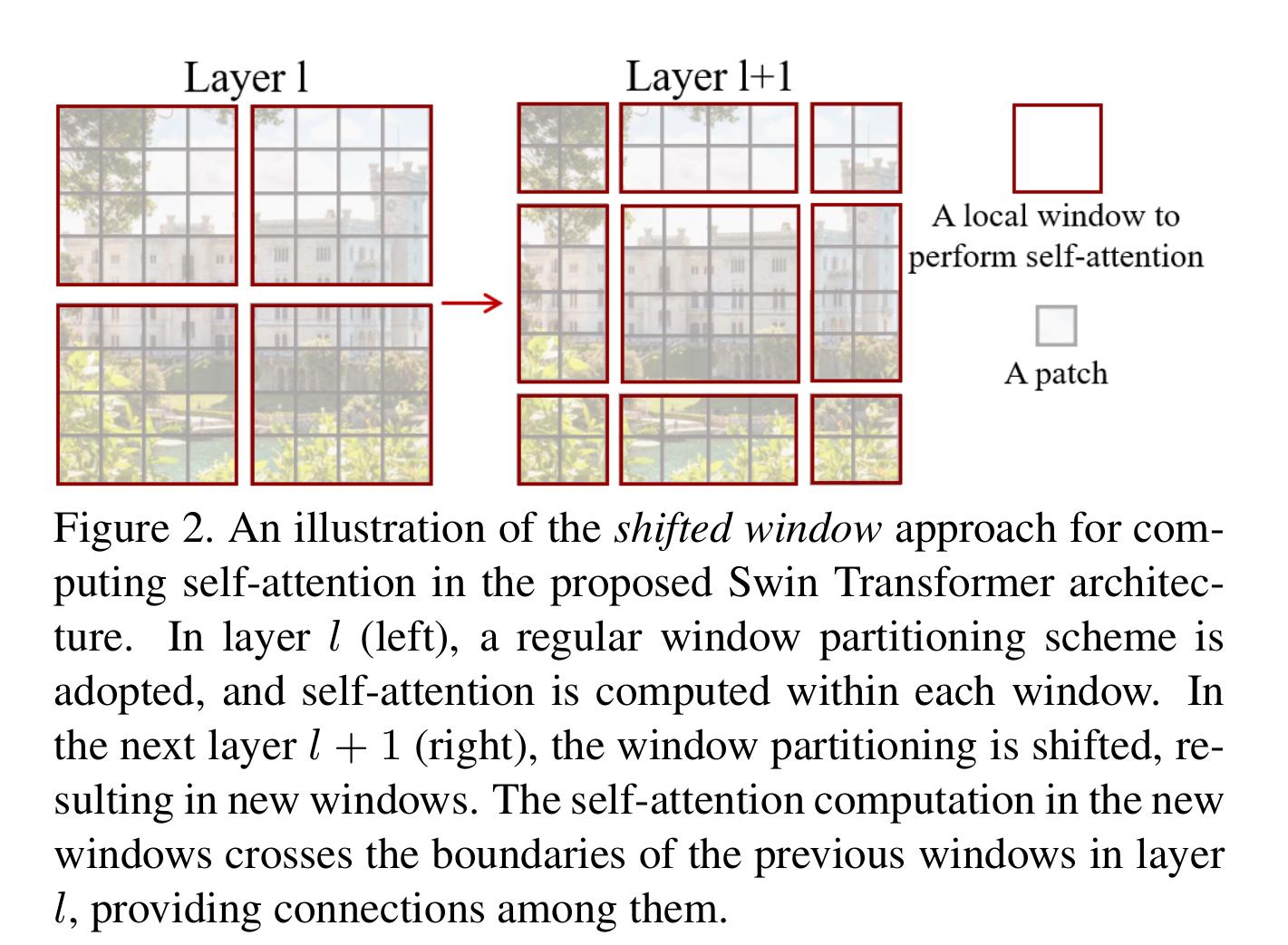
This shifting scheme introduces new connections across windows
Experiments
-
The method is evaluated on three tasks:
-
image classification : ImageNet-1K
-
object detection : COCO
-
semantic segmentation : ADE20K
-
The paper presents four model variants:
- Swin-T: C = 96, layer numbers = {2, 2, 6, 2}
- Swin-S: C = 96, layer numbers ={2, 2, 18, 2}
- Swin-B: C = 128, layer numbers ={2, 2, 18, 2}
- Swin-L: C = 192, layer numbers ={2, 2, 18, 2}
Image classification on ImageNet-1k
- Training from scratch on ImageNet-1k
- Swin Transformers surpass others transformers architecture (DeiT architecture and ViT architecture)
- And is comparable with convolution based architecture (EfficientNet and Regnet)
- Pre-training on ImageNet-20k and fine tuning on ImageNet-1k
- Pre-training improves the results but it’s less significant than ViT
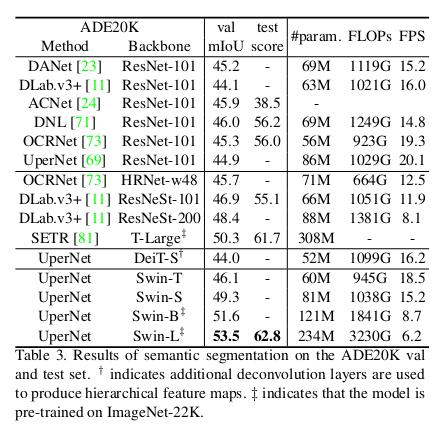
Object Detection on COCO
-
Comparison with ResNet and DeiT (transformer) as a backbone for object detection framework
-
Swin Transformers surpass previous state-of-the-art
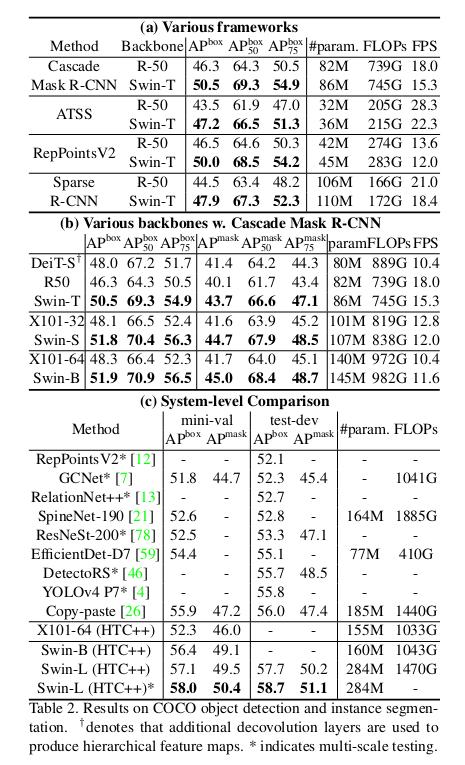
Semantic Segmentation on ADE20K
- Comparison with different method/backbone pairs
- With the same method (UperNet) Swin-T is a better backbone than ResNet-101 and DeiT-S
Ablation study on shifted windows
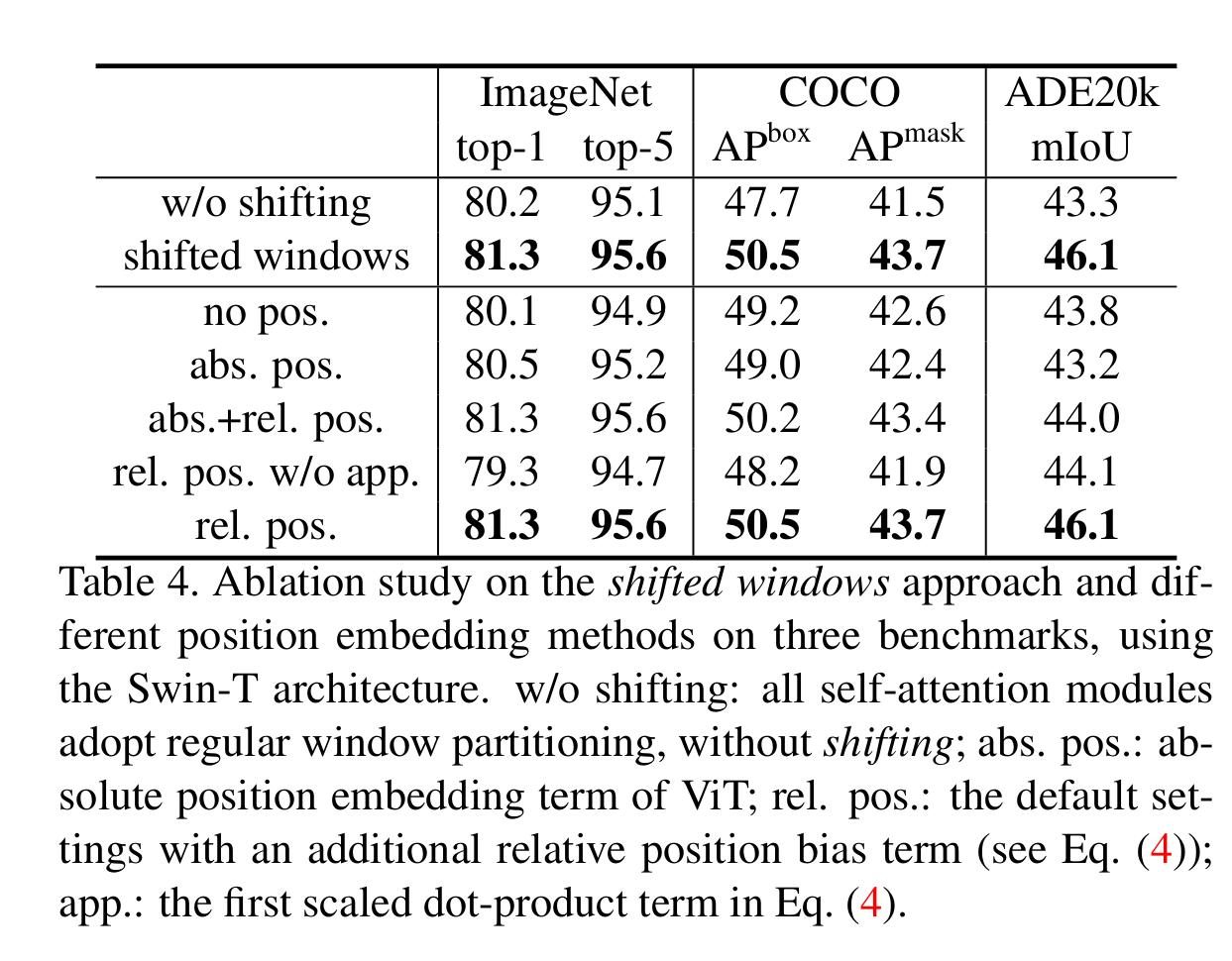
Ablation study shows that the shifted windows method is neccesary to build connections among windows
Conclusions
Swin Transformers achieve state-of-the-art performance on several vision tasks. Thanks to the linear computational complexity Swin Transformers seem to be more a scalable backbone for transformer based architecture.