PerceptFlow: Real-time ultrafast Doppler image enhancement using CNNs and perceptual loss
Context
- Ultrafast Doppler imaging allows the acquisition of functional vascular transcranial images. The procedure needs to be real-time and have a high contrast between the vessels and the background.
- Accumulation of several frames is performed to produce each image.
- The skull attenuates the ultrasound signal, resulting in poor contrast.
- Classic enhancement techniques are i) Gaussian filter (GF) and ii) block matching and 3D filtering (BM3D). But they are slow and they tend to over-smooth the images.
- The authors introduce PerceptFlow, a self-supervised CNN that improves the contrast of transcranial Doppler images of mice.
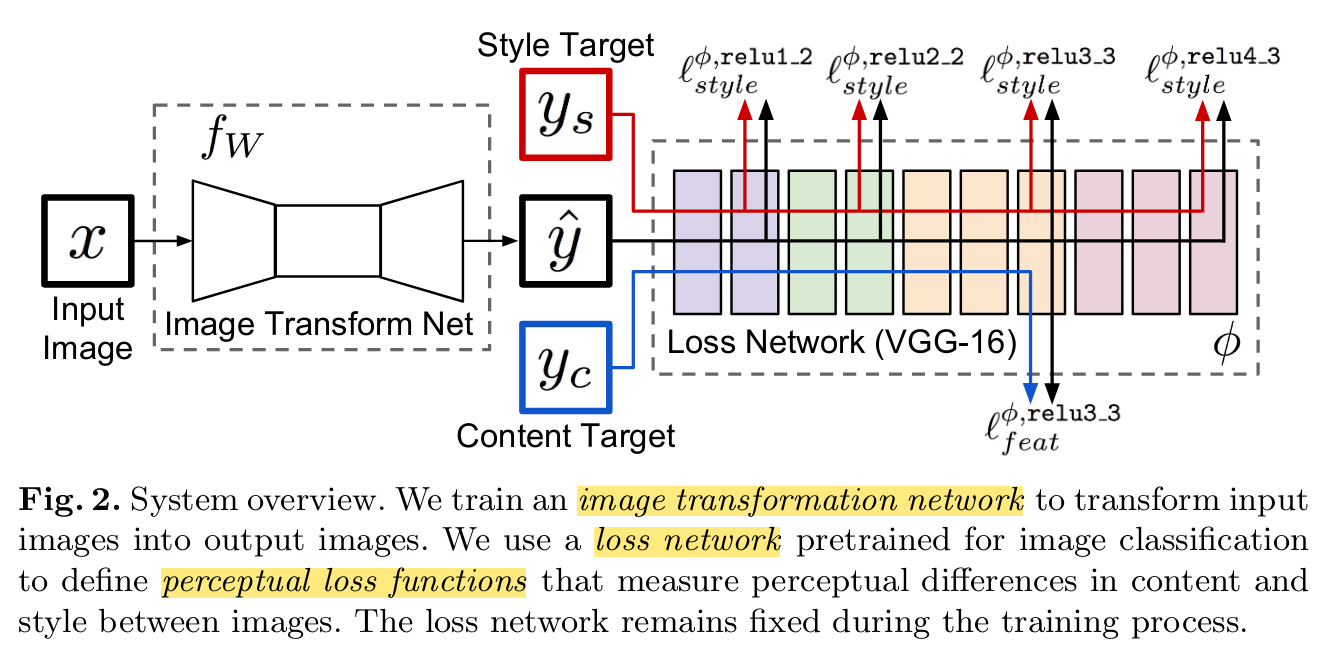
- They use a perceptual loss function, introduced originally by Johnson et al (2016) [1] for the purpose of style transfer.
Johnson et al were interested in a loss function that imposed the style and the content of some given images to the output image. VGG16 trained on ImageNet is known for extracting high-level content features in the deep layers. Hence, they used VGG16 as a pre-trained loss network to define the loss function of the main network. The perceptual loss function minimizes the difference between VGG16 content features of a given reference image and the output image.
Methods
Self-supervised strategy
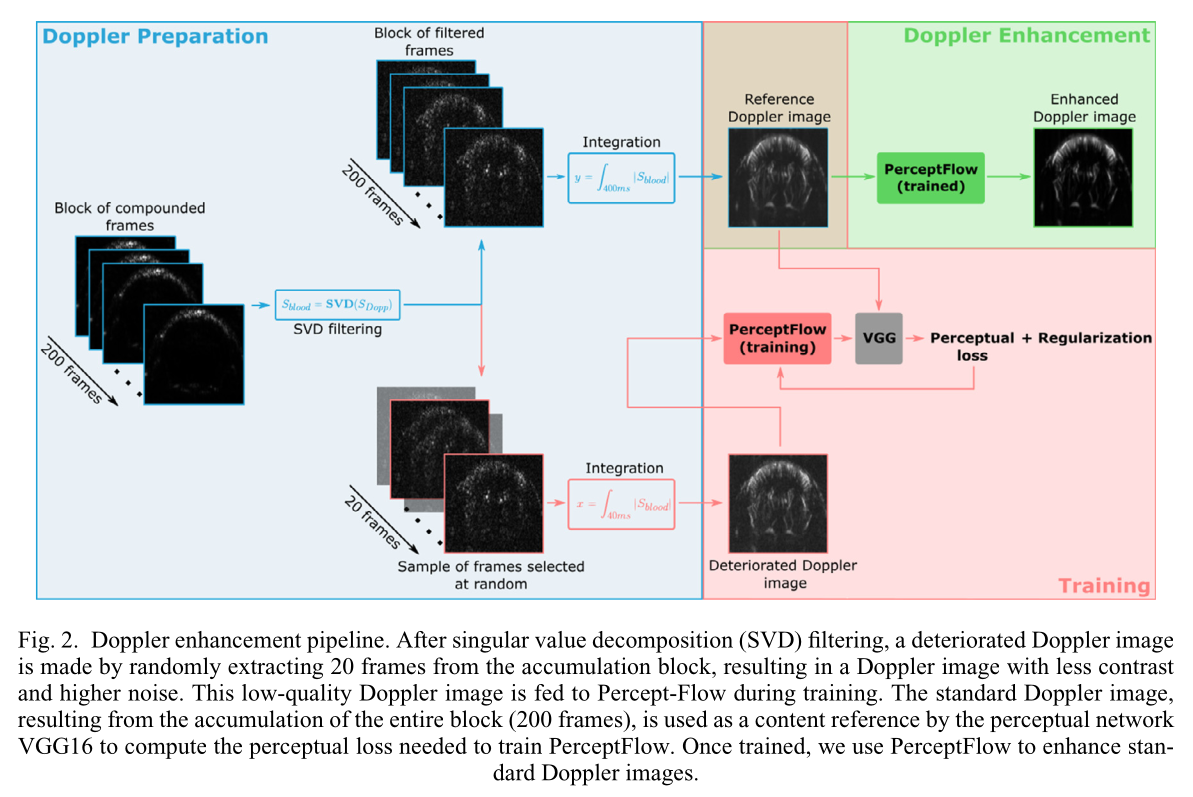
16,000 in vivo Doppler images are acquired in mice. Each image is generated by accumulating 200 frames acquired during 400 \(ms\) to improve quality. There are no ground-truth high-quality images, so they build a training dataset by deteriorating the quality of their images. The input image \(x\) is generated by keeping only 20 random frames, and its reference \(y\) is the image generated with the total 200 frames.
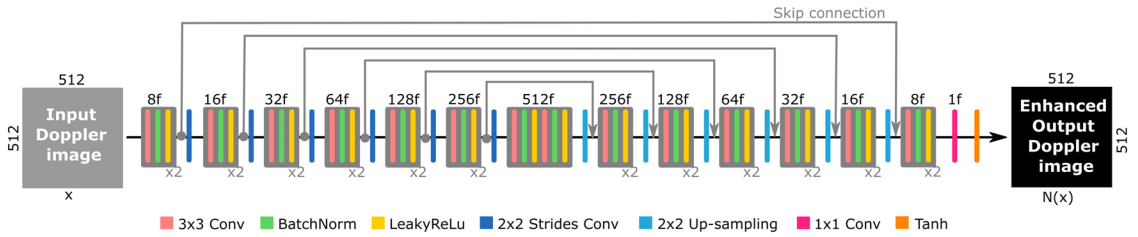
Enhancement network
The enhancement network is based on the U-Net architecture and takes an image \(x \in \mathbb{R}^{512 \times 512}\) and outputs an enhanced image \(N(x) \in \mathbb{R}^{512 \times 512}\).
Perceptual network
They are interested in enhancing the contrast between the vessels and the background while preserving the vasculature of the images. Hence, they want the image content to be conserved. They use VGG16 to define the perceptual loss by freezing all weights. VGG16 will account for the preservation of the vasculature.
Perceptual loss and regularization terms
Given the input image \(x\), its reference \(y\) and the content feature space of dimension \(h' \times w'\),
\[L_{\text{perceptual}} = \mathbb{E}_{x,y} \left[\begin{array}{c} \frac{1}{h' w'} \sum (\text{VGG16}(N(x))-\text{VGG16}(y))^2 \end{array}\right]\]To force high contrast in the output and taking advantage of the fact that no pixel-wise loss function is used, they add 2 regularization terms:
- minimise the intensity of third quartile pixels (impose low intensity in the background)
- minimise the intensity difference between the reference and the output of maximum intensity pixels (impose maintained intensity in vessels).
Pipeline
Results
- PerceptFlow produces enhanced images while preserving the vasculature.
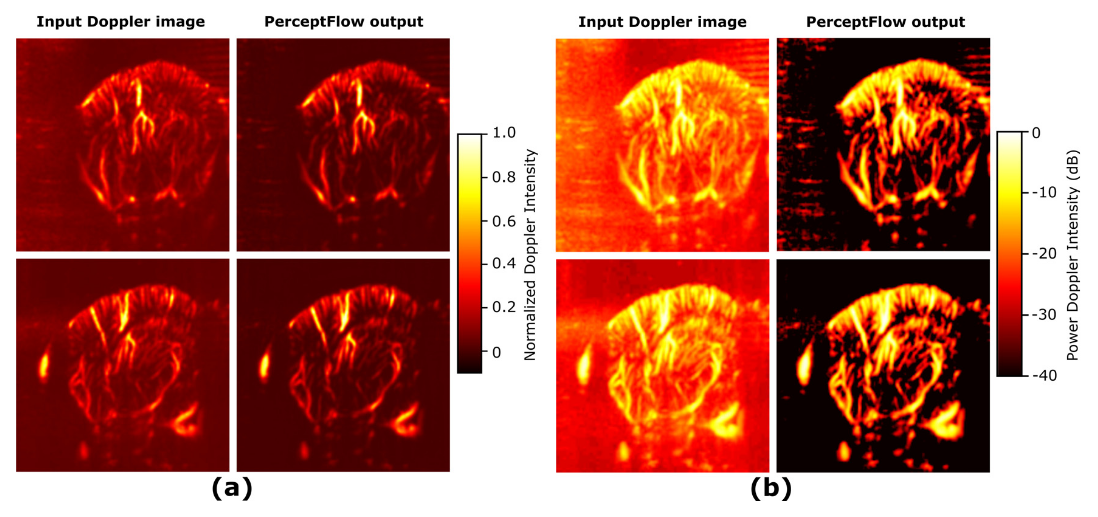
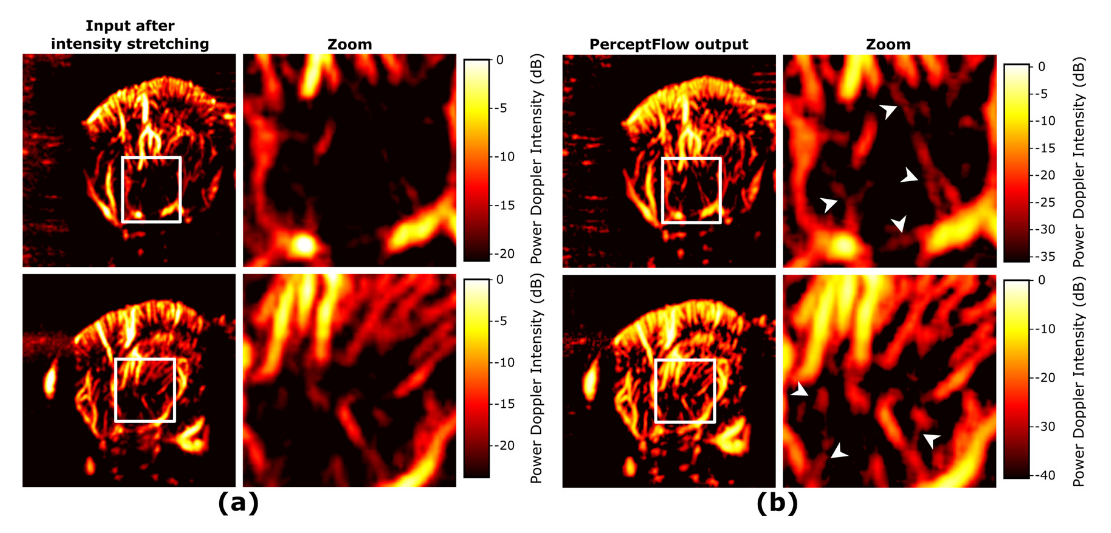
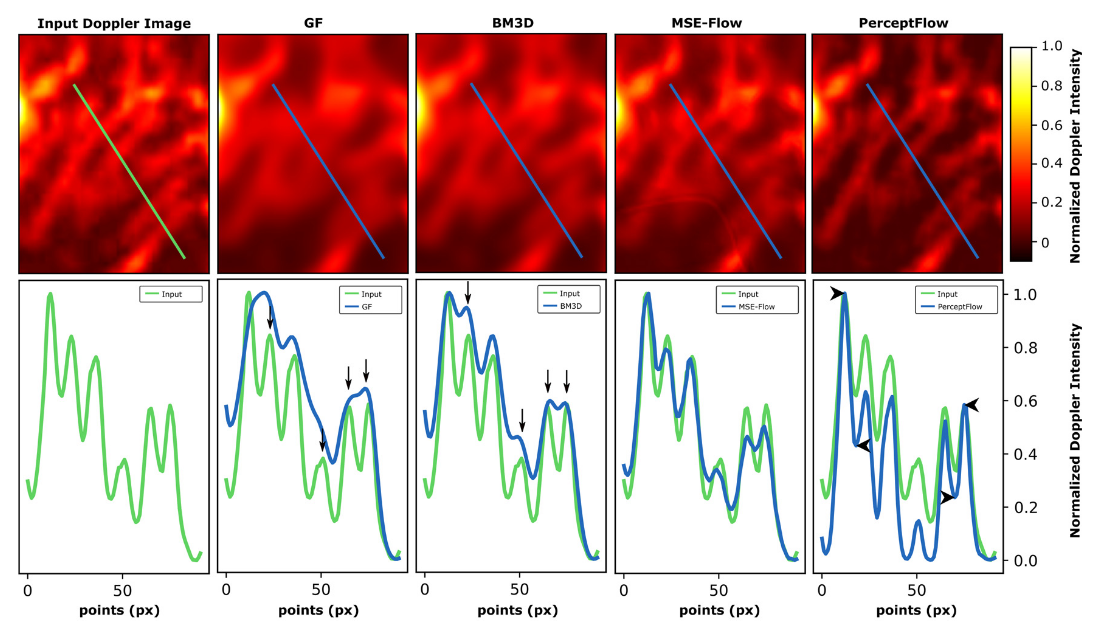
- They outperform classic methods and the MSE-based CNN in terms of contrast.
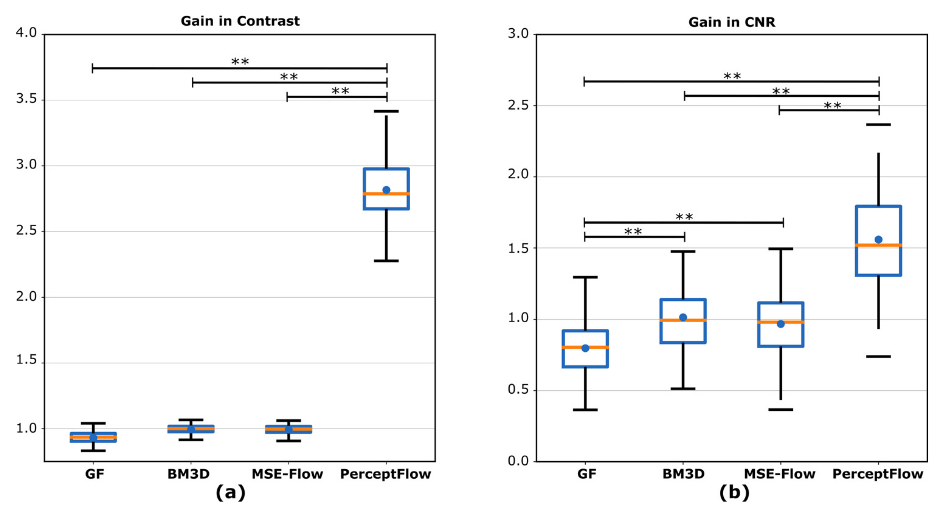
Conclusion
- PerceptFlow produces enhanced Doppler images with higher contrast and CNR, preserved resolution and vasculature, and good visual quality.
- The perceptual loss allows to add pixel intensity regularization terms.
- Perceptflow generalizes well to other animal models.
- Drawbacks:
- the regularization terms are manually set.
- non-linear operations may affect the quantitative measurement of blood flow.