SAM: Segment Anything Model
Notes
- All information and demo is available here
Highlights
- This paper proposes a foundation model for segmentation.
- It allows real time segmentation with zero-shot transfer based on a simple prompt.
- With it, a new vision dataset is released with more than 1.1B masks on 11M images, called SA-1B.
Introduction
Following the trend of foundation models such as CLIP1 in natural language processing that can generalize to tasks and data distributions beyond those seen during training, Segment Anything Model (SAM) is proposed as a foundation model for segmentation tasks, as there are only fine-tuned models in this domain. This model is a promptable model pretrained on a large dataset that enables powerful generalization without transfer learning. To do so, a data engine is used to train and create a new large dataset.
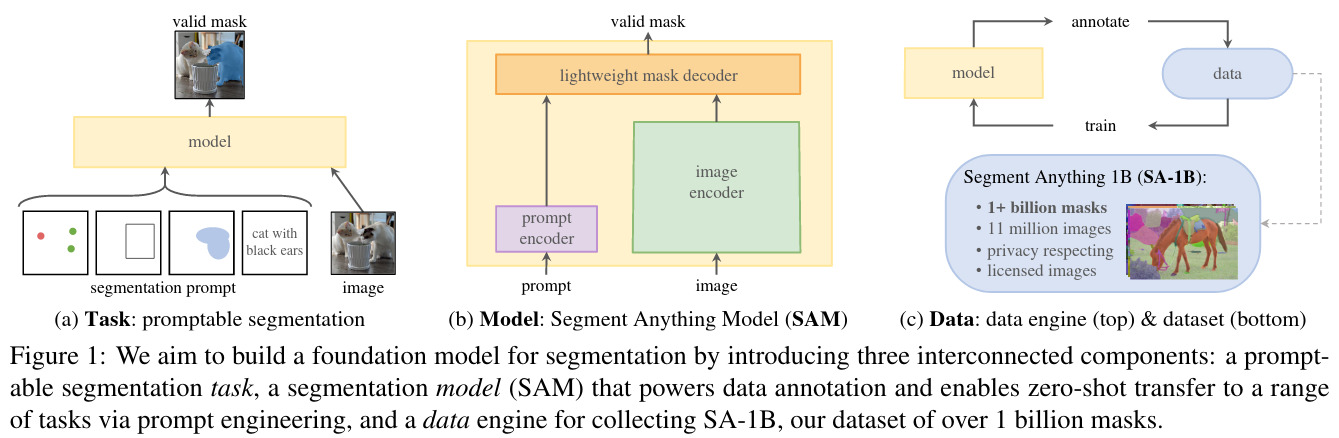
Definition of the task
There is a transfer of the NLP prompt to segmentation with selection of foreground or background points, a box, a rough mask, a text or any information indicating what to segment in an image. The input might be ambiguous, in this case the model must be valid for at least one object.

Usually, promptable and interactive segmentation uses a sequence of inputs to eventually predict a valid mask. The goal here is to have a valid mask for any prompt even when it is ambiguous. The pre-trained model must be effective in those cases which is challenging and requires specialized modelling and training loss choices. Good prompt engineering must be found to succeed in a zero-shot transfer to any task linked to segmentation such as interactive segmentation, edge detection, super pixelization, object proposal generation, foreground segmentation, semantic segmentation, instance segmentation, panoptic segmentation, etc. It differs from a multiple-task segmentation model as the model is not trained for a fixed set of tasks but can be applied to a new task it was not trained for thanks to prompting and composition.
Segment Anything Model
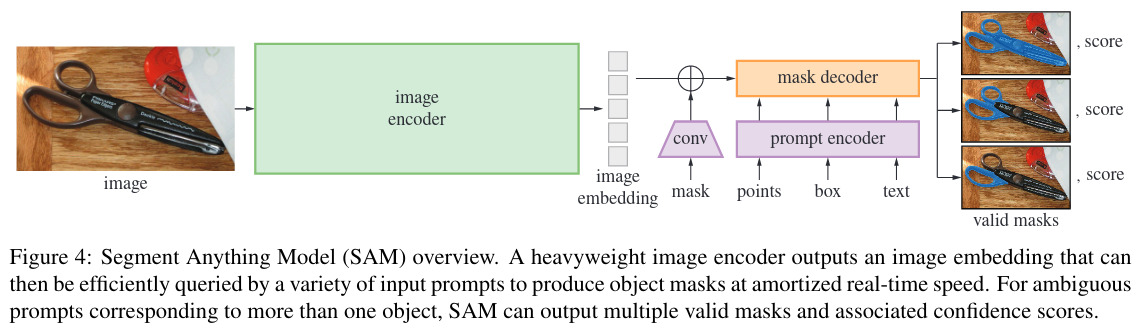
The image encoder is a Masked AutoEncoder (see previous post) pre-trained Vision Transformer (ViT) adapted to high-resolution inputs.
The prompt encoder is separated between sparse prompts (points, boxes, text) where positional encoding, or text encoding with CLIP, is summed with embeddings learned for each prompt type, and dense prompts (mask) where inputs are embedded using convolutions and summed element-wise with the image embedding.
The mask decoder is a modification of a Transformer decoder block using self-attention and cross-attention followed by a dynamic mask prediction head.
To resolve ambiguity between the 3 different output masks a confidence score (mIoU) is calculated to rank them.
Mask prediction is supervised with focal loss and dice loss. The training for the promptable segmentation task is done using a mixture of geometric prompts. They simulate an interactive setup by randomly sampling prompts in 11 rounds per mask, allowing SAM to integrate seamlessly into the data engine.
Data Engine
The SA-1B dataset is constructed in 3 steps.
Assisted manual stage
SAM is first trained with a publicly annotated dataset and professional annotators use it with foreground/background clicks and readjust the masks with brush and eraser tools. They annotate as many objects as possible in the images in order of prominence. The model is retrained 6 times while the quantity of data augment without the public dataset at time the quantity of newly annotated data is enough.
Semi automatic annotation
This second step is to increase the data diversity. This time SAM segments first the images trained with boxes and with the category “object” and then the annotators add new masks to the images. It is retrained 5 times, and the number of masks increases from 44 to 72 per image.
Fully automatic
The ambiguity aware mechanism is added in this last step. It proposes only stable and confident masks thanks to a good probability map and the mIoU score. The quality of little masks is improved with overlapping zoomed in image crops. In the end there are 1.1B masks in 11M images.
SA-1B Dataset
Mean resolution of images is 3300x4950 pixels and even when downsampling the images, it is of better quality than other vision datasets. 99.1% of masks are generated automatically but the final SA-1B only contains automatically generated masks.
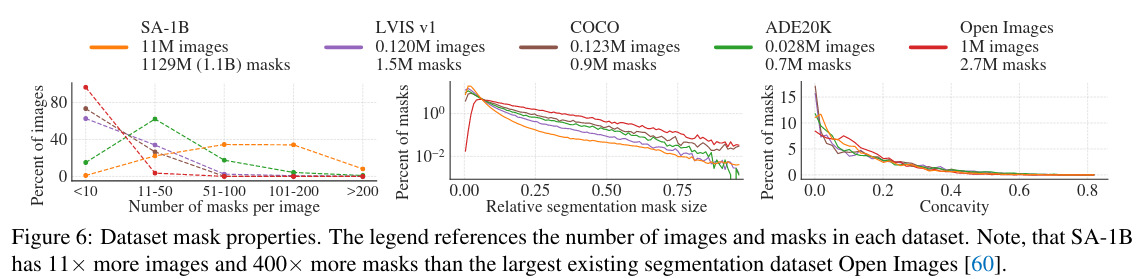
To assess the quality of the masks, 500 images are sampled (~50,000 masks) and annotators correct the masks with a brush and eraser. Comparing raw masks and corrected ones, 94% of the automatically generated masks have an IoU >90% and 97% have an IoU >95%.
Responsible AI analysis
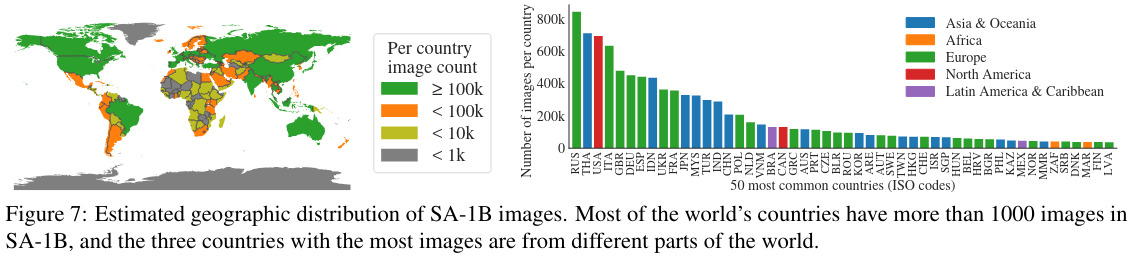
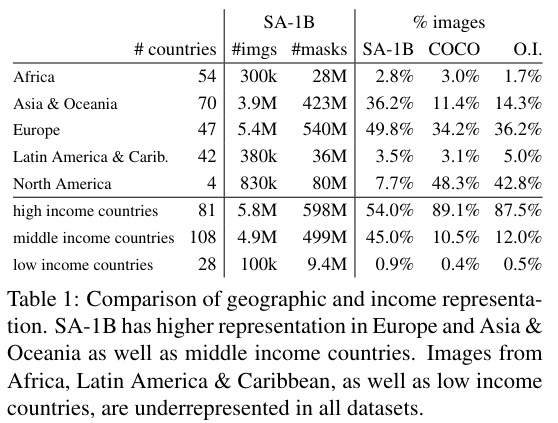
The top 3 countries are from different regions in the world and even if Africa and low-income countries are underrepresented, there are 28M masks from Africa which is 10 times more than all other datasets together. It would have been interesting to see those numbers in relation to the number of inhabitants and compare it to other datasets regarding the number of masks in them.

The More Inclusive Annotation for People is used to see whether there was a biais between gender, age or skin color in the segmentation with 1 to 3 points.
Zero Shot transfer learning
As the goal of SAM is to be a foundation model adapted to all image types and a lot of tasks related to segmentation, they test segmentation with 1 point as it is the most ambiguous prompt and 4 other tasks that differs from what SAM is trained for.

23 new datasets are used to test SAM with novel image distribution that do not appear in SA-1B. SAM uses a MAE pre-trained ViT-H autoencoder and is trained with SA-1B that only contains automatically generated masks.
Segmentation with one point prompt
SAM is compared with RITM which is an interactive segmentor that works well on their benchmark compared to others.
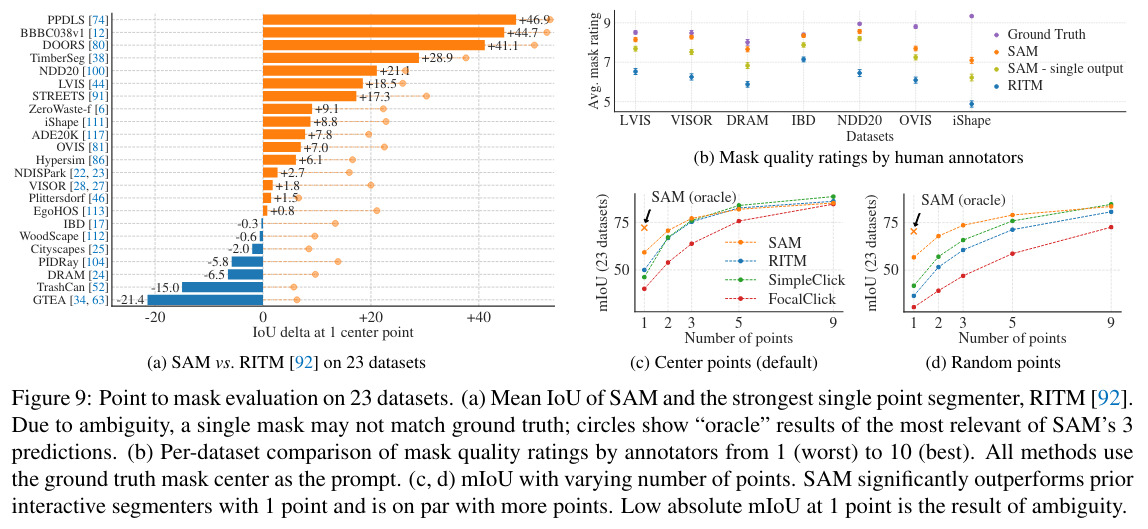
Both mIoU and human ratings of the masks between 1 to 10 are compared. On 16 out of 23 datasets SAM performs better than RITM but when an oracle selects the best mask according to the ground truth (and not the selection of the most confident mask) SAM is better on all datasets. Looking at the datasets on which this change allows a great improvement could be interesting. When human rating is considered, SAM masks are better than RITM’s ones even when the IoU is worse. The more there are prompted points, the less SAM is better than the other except when the points are not centered.
Edge detection
A 16x16 grid of points is applied to all images which leads to 768 masks per image (3 per point). The redundancy is removed with Non-Maximal Suppression (NMS) and a Sobel filter is applied on un-thresholded masks probability masks to have edges.
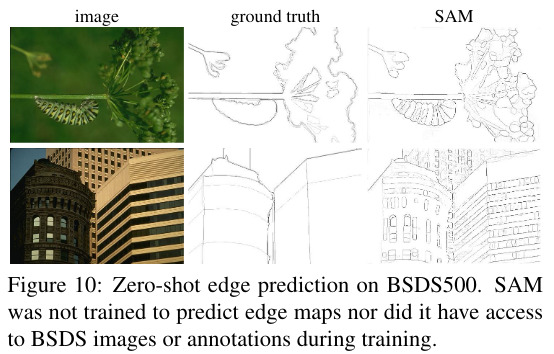
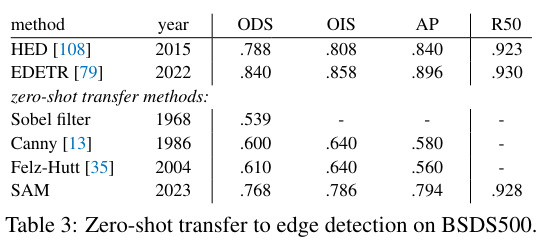
Even if SAM is not trained for that the results are not bad but includes sensible edges that were not even annotated.
Object proposal
The mask generation pipeline is modified to make mask proposals. They concentrate on LVIS dataset as there are many categories and compare SAM to a ViTDet detector.
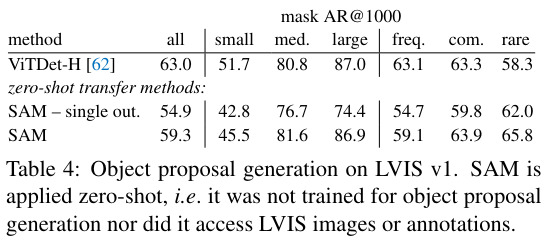
SAM is not as good but is competitive on big objects.
Instance segmentation
The boxes of ViTDet are used as prompt on COCO and LVIS datasets. It is an example of compostion of SAM to a larger system.
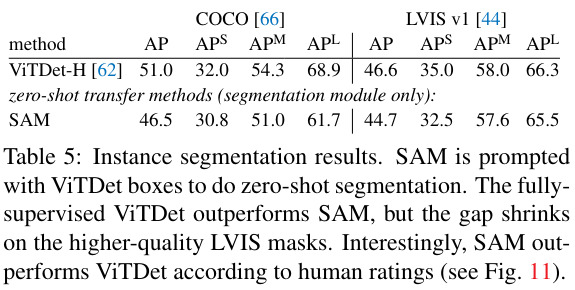
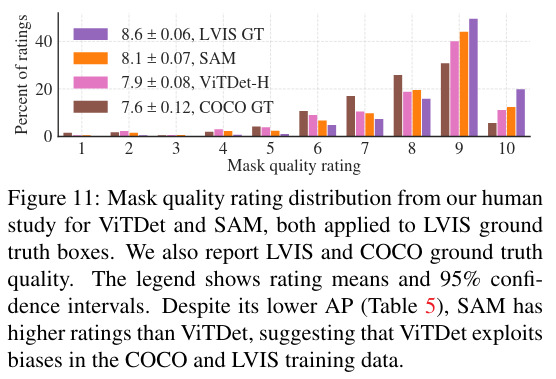
In comparison with ViTDet-H, SAM’s performance is not as good but is not far. According to human rates it is better. The case of COCO is particular as the ground truth has many defaults, that are learned by the network, what SAM doesn’t do.
Text to mask
Segmenting an image from text input is a proof of concept of SAM’s ability to process text prompt. This time SAM is trained differently but without the need of new text annotation. For each masks with an area \(>100^2\), the CLIP image embedding is extracted and during training those embeddings are prompted at its first interaction. During the inference the text is run through CLIP’s text encoder which is then prompted to SAM.

Ablations
The ablations concern the SA-1B dataset and the architecture of SAM.
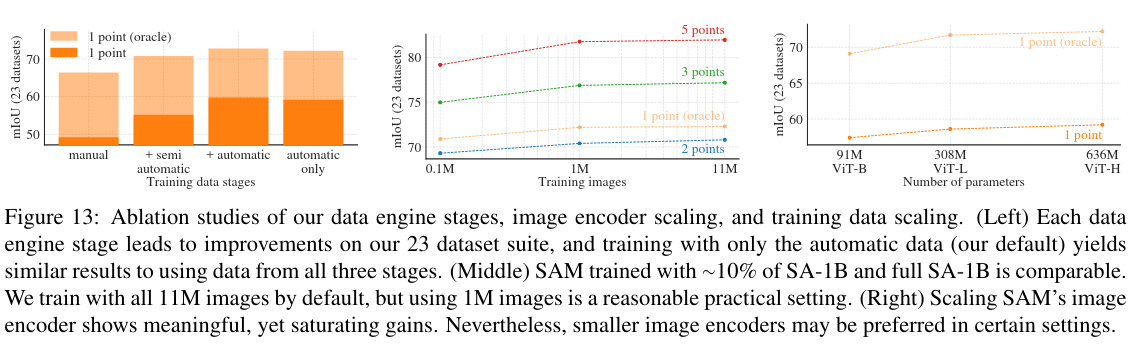
The performance increase through all the data engine steps but in the end only images with automatically generated masks are kept to simplify setup training.
Discussion
Models are almost always dedicated to a particular task, but here the foundation model trained on a very large dataset is then adapted to many tasks. However, generally foundation models are auto-supervised whereas here it is initialised with a MAE trained using supervised labels.
The goal of SAM is to be used in composition systems (like CLIP in DALL-E) in order to get new capabilities that were not even thought about at its creation. To do so, SAM needs to predict a valid mask for a wide range of segmentation prompts in order to create a good interface between SAM and other components.
It still has some limitations, there are some errors missing small structures or creating small disconnected components, and does not produce boundaries as crisply as more computationally intensive methods. Given the fact that it is a very generic segmentation model whose goal is to perform with zero transfer learning, it is expected that all dedicated interactive segmentation methods should outperform SAM. Another limitation is the computational time: it is said to be real-time but it is not really the case when using a heavy image encoder. Finally even if SAM performs many tasks, it is not easy to design simple prompts that implement semantic and panoptic segmentation.
References
-
A. Radford et al. Learning Transferable Visual Models From Natural Language Supervision. https://doi.org/10.48550/arXiv.2103.00020 ↩