Multi-Modal Masked Autoencoders for Medical Vision-and-Language Pre-Training
Notes
- Here are some useful links: repo, submission process
Highlights
- The objective of this paper is to develop a self-supervised learning paradigm which can learn cross-modal domain knowledge (vision and language) from medical data.
- The self-supervised strategy is based on the reconstruction of missing pixels (vision) and text labels (language) from randomly masked images and texts.
- The evaluation is based on a medical vision-and-language benchmark which includes three tasks.
Motivations
-
Medical vision-and-language pre-training (Med-VLP) aims to learn generic representations from large-scale medical image-text data
-
This representation can be transferred to various tasks relevant for medical vision-and-language analysis, such as visual question answering, image-text classification, image-text retrieval (the corresponding definitions are given below)
Method
Architecture
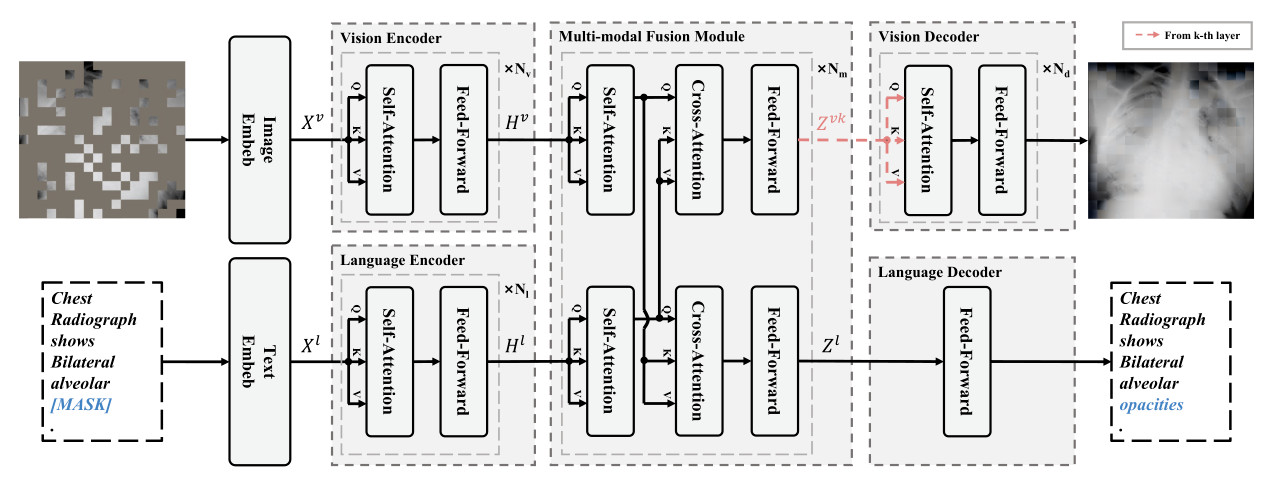
Key aspects
-
Use of transformers to encode image and language features
-
Use of transformers to perform multi-modal fusion
-
Use of a transformer to decode the image and a simple MLP to decode the text
-
pre-training is performed using medical image-text pairs
- Masks random patches of the input image and random tokens of the input text and reconstructs the missing pixels and tokens
this makes pre-training a self-supervised process
- Uses different masking rates for input images and text due to the different information densities of vision and language
Formalism
Loss function
\[\theta^{*},\theta_1^{*},\theta_2^{*}=\arg \min_{\theta,\theta_1,\theta_2} \sum_{s=1}^{2} L_s\left( Y_s,D_{\theta_s} \left( M_{\theta}(I,T) \right) \right)\]-
\(L_s\) are the loss functions of pretext tasks, i.e MSE between the reconstructed and original images and the negative log-likelihood for the masked tokens
-
\(D_{\theta_s}\) are the decoders with their parameters \(\theta_1\), \(\theta_2\)
-
\(M_{\theta}\) is the backbone model with its parameters \(\theta\).
Vision encoder
\[X^{\nu} \in \mathbb{R}^{(N+1) \times D} \,=\, \left[ p_I; p_1 E^{\nu}; \cdots; p_N E^{\nu} \right]\,+\,E^{\nu}_{pos}\]-
Each image \(I \in \mathbb{R}^{H \times W \times C}\) is divided into \(N\) patches \(\{ p_1,\cdots,p_N \}\)
-
\(E^{\nu} \in \mathbb{R}^{P^2 \times D}\) is the projection matrix into the patch embeddings
-
\(p_I \in \mathbb{R}^{D}\) is used for the aggregation of visual information
-
\(X^{\nu}\) is fed into a transformer model with \(N_{\nu}\) transformer blocks to obtain the contextualized image representation \(H^{\nu} \in \mathbb{R}^{(N+1) \times D} \,=\, \left[ h^{\nu}_I; h^{\nu}_1; \cdots; h^{\nu}_N \right]\)
Language encoder
\[X^{l} \in \mathbb{R}^{(M+2) \times D} \,=\, \left[ w_T; w_1 E^{l}; \cdots; w_M E^{l}; w_{SEP} \right]\,+\,E^{l}_{pos}\]-
Each input text is tokenized to subword tokens \({w_1,\cdots;w_M}\) by WordPiece, where tokens \(w_m \in \mathbb{R}^{V}\) are represented in one-hot form and \(V\) is the vocabulary size
-
\(E^{l} \in \mathbb{R}^{V \times D}\) is the projection matrix into the text embeddings
-
\(w_T \in \mathbb{R}^{D}\) and \(w_{SEP} \in \mathbb{R}^{D}\) correspond to a start-of-sequence token embedding and a special boundary token embedding, respectively
-
\(X^{l}\) is fed into a transformer model with \(N_{l}\) transformer blocks to obtain the contextualized text representation \(H^{l} \in \mathbb{R}^{(M+2) \times D} \,=\, \left[ h^{l}_T; h^{l}_1; \cdots; h^{l}_M; h^{l}_{SEP} \right]\)
Masking scheme
- the authors used random sampling with a much greater masking ratio for images (i.e. \(75\%\)) than for texts (i.e. \(15\%\)). This is justified by the fact that images are redundant while languages are information-dense
Representation selection for reconstruction
-
Images and texts are abstracted at different levels, with pixels having a lower semantic level than text tokens.
-
The outputs from the \(k\)-th transformer block (\(Z^{\nu k}\)) are used to compute the reconstruction loss (red part in the figure of the architecture)
-
The final output \(Z^{l}\) is used for the prediction of text tokens since predicting missing words requires richer semantic information
Decoder designs
-
A transformer model is used to perform the reconstruction task from \(Z^{\nu k}\)
-
A simple MLP is used to retrieve the missing text tokens
Results
ROCO dataset - repo
- 81,000 medical images with their captions and the corresponding UMLS Semantic Types useful for classification purposes
UMLS (Unified Medical Language System): provides a standardized way of categorizing biomedical concepts based on their semantic characteristics.
-
Contains several medical imaging modalities with the corresponding text automatically extracted from PubMed Central Open Access FTP mirror
-
There are 16 times more radiological images than the others modalities
- Randomly split the dataset into 80/10/10.
MedICaT dataset - repo
-
217,000 medical images from with their captions and inline textual references for 74% of figures
-
Contains several medical imaging modalities with the corresponding text automatically extracted from PubMed Central Open Access FTP mirror
-
Randomly sample 1,000 images for validation, 1,000 images for testing, and the remaining images for training
Implementation details
-
Vision encoder: CLIP-ViT-B
-
Language encoder: RoBERTa-base
-
\(N_m=6\) transformer blocks for the multi-modal fusion module with a number of heads of 12 per block
-
AdamW optimizer during pre-training for 100,000 iterations
-
Center-crop to resize each image into the size of 288x288
Downstream tasks
-
Medical Visual Question Answering (Med-VQA) - Answering natural language questions about medical images. VQA-RAD, SLAKE and VQA-2019 dataset were used for evaluation
-
Medical Image-Text Classification - Produce the label given an image-text pair. The MELINDA dataset was used for evaluation
-
Medical Image-Caption Retrieval - Two subtasks: image-to-text (I2T) retrieval requires retrieving the most relevant texts from a large pool of texts given an image and vice versa for text-to-image (T2I). The ROCO dataset was used for evaluation
-
Accuracy is used as metric for the Med-VQA and medical Image-Text classification tasks
-
Recall@K (K=1, 5, 10) is used for the Medical Image-Caption Retrieval task
Unfortunately, nothing is said concerning the fine-tuning of the pretrained methods for the different downstream tasks :(
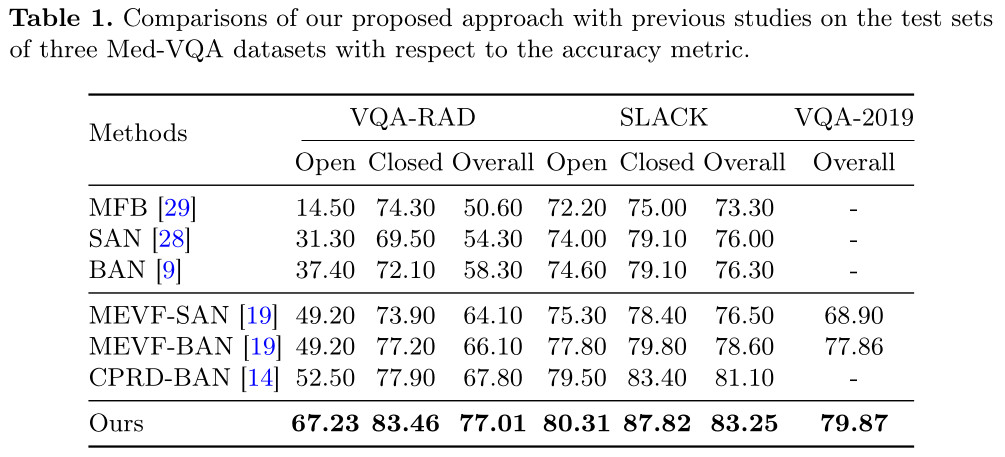
Results for Med-VQA task
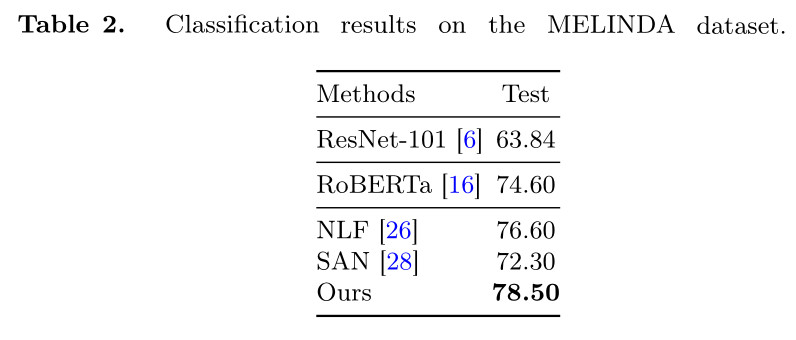
Results for Medical Image-Text Classification
Results for Medical Image-Caption Retrieval
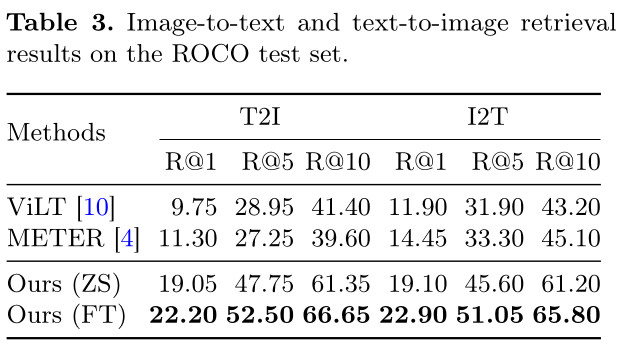
(ZS) means zero-shot and (FT) means fine-tuning
Ablation study
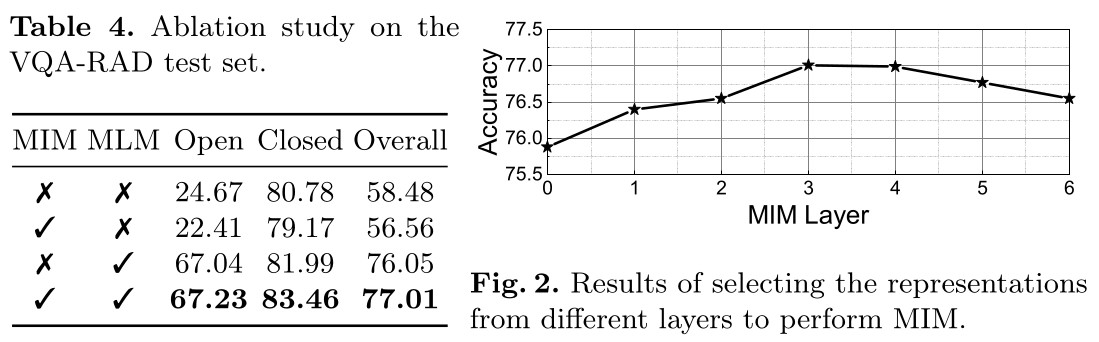
(MIM) stands for Masked Image Modeling and (MLM) stands for Masked Language Modeling
Qualitative results
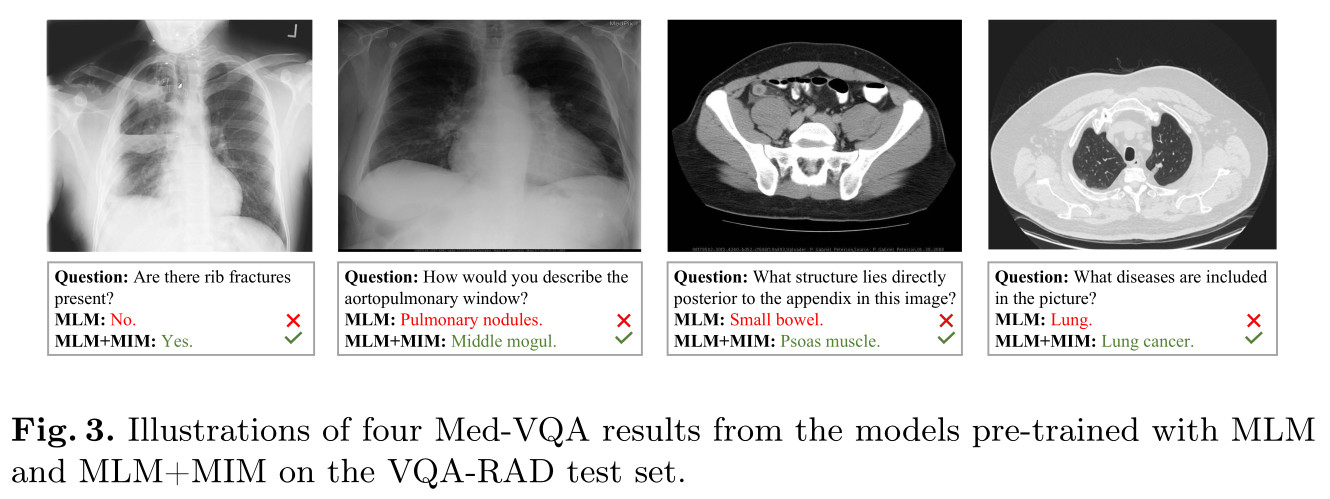
Conclusions
-
Image/text coupling for medical data analysis looks like a promising way forward
-
Pre-training in a self-supervised way using a masking strategy appears to be relevant
-
Exploiting embeddings at different levels of abstraction for images and text would seem to be a good approach