Segment Any Medical Image
Note
This is a combined review of the four following papers. The aim is to give an idea about how Segment Anything (SAM)1 has been used and adapted to medical images since its release in April 2023.
- J. Ma, Y. He, F. Li, L. Han, C. You, B. Wang, Segment Anything in medical imaging, April 2023, link to paper.
- K. Zhang, D. Liu, Customized Segment Anything Model for Medical Image Segmentation, April 2023, link to paper.
- J. Wu, R. Fu, Y. Zhang, H. Fang, Y. Liu, Z.Wang, Y. Xu, Y. Jin, Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation, April 2023, link to paper.
- X. Lin, Y. Xiang, L. Zhang, X. Yang, Z. Yan, L. Yu, SAMUS: Adapting Segment Anything Model for Clinically-Friendly and Generalizable Ultrasound Image Segmentation, September 2023, link to paper.
Highlights
- Segment Anything performs badly on medical images, mainly because of the domain shift as it has only been trained on natural images
- Several methods have been proposed to leverage SAM’s architecture and training and finetune it on medical datasets
- Most if them rely on Adaptation Modules added in SAM’s Transformer architecture
Introduction
Recently, the Segment Anything Model has had a resounding impact on the field of foundation models for image segmentation. Its main strength is to leverage a huge dataset with 1.1B masks in 11M images annotated in a three-stage process. Even though it has shown amazing performances at zero-shot transfer learning on many tasks, these performances poorly generalize to medical images2. As SAM has only been trained on natural images, that are semantically far far from medical images, this result may not be that surprising. Moreover, it has been shown that SAM’s abilities vary a lot depending on the dataset, the task and the input prompt (Fig. 1).
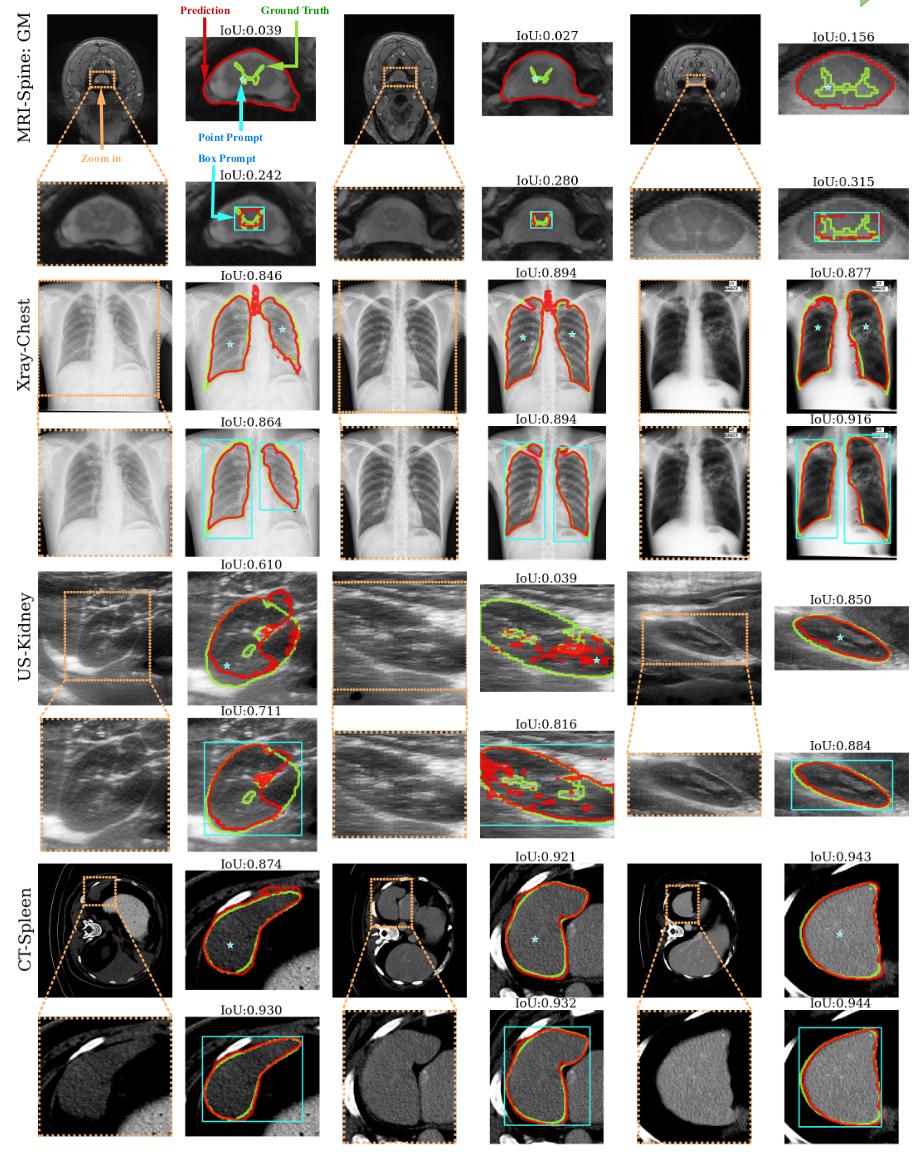
Figure 1.Examples of results of SAM on various medical imaging tasks.
However, one can believe that it may be useful to leverage SAM’s huge training and finetune its architecture to get a new version more suited to medical imaging tasks. Several approaches have already been developed, and we propose to present some of the main ones here.
Quick reminder on Segment Anything Model
SAM’s architecture is composed of three main parts : an image encoder, prompts encoders and a lightweight mask decoder.
- The encoder is a masked auto-encoder (MAE) pre-trained ViT-H/16
- Text prompt is encoded with CLIP text encoder and the sparse prompts are mapped to 256-dimensional vectorial embeddings with positional encoding.
- The decoder is composed of only 2 Transformer’s decoder blocks with prompt tokens to image embeddings and image embeddings to prompt tokens cross-attention. The resulting embeddings are upscaled with transpose convolution to the input image size and an additional MLP predicts the IoU score with the target object.

Figure 2. Segment Anything Model overview.
For an extended review of SAM, please refer to this post.
Presentation of the methods
Segment Anything in Medical Imaging (MedSAM)
- Architecture copied from SAM, with a lighter ViT as image encoder. 89M and 4M parameters respectively for the encoder and the decoder.
- The prompt encoder is frozen.
- Combination of cross-entropy and dice loss
- 1.0M+ medical image-mask pairs covering 15 imaging modalities and over 30 cancer types
Customized Segment Anything Model for Medical Image Segmentation (SAMed)
- Use pre-trained SAM and freeze all the parameters in the image encoder
- Add a Low-Rank Adaptation module (LoRA)3 to each transformer block (see Fig. 3).
LoRA is an efficient finetuning strategy for large-scale models that aims to condense the transformer features to a low rank space and then reproject them to the dimensions of the output features in the frozen transformer blocks. The feature size in the projected LoRA space is divided by 4.
- The updated model only increases the original model size by 5.25% (+18.8M parameters)
- All the parameters in the prompt encoders and the mask decoder are finetuned (LoRA in the mask decoder’s transformer blocks was tested but yielded lower results).
- 30 abdominal CT scans from the MICCAI 2015 Multi-Atlas Labeling Challenge are used for training/validation and the model is then evaluated on the Synapse multi-organ segmentation dataset.
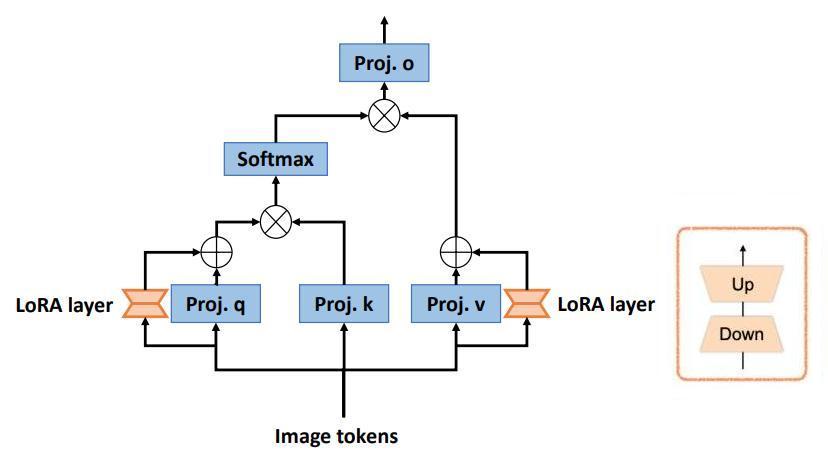
Figure 3. Low-Rank Adaptation design adopted in SAMed.
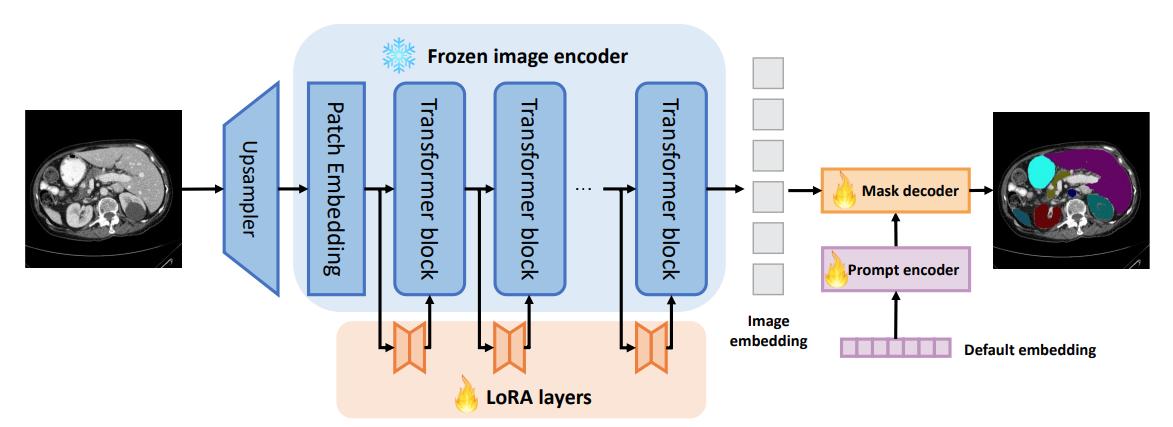
Figure 4. The pipeline of SAMed.
Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation (MSA)
- Two LoRA modules at each block of the transformer encoder
- To better handle 3D images, the authors use a strategy inspired by image-to-video adaptation:
For a sample DxNxL (with D the depth, N the number of embeddings and L their size), a first multi-head self-attention acts over NxL to learn spatial correlation. Additionally, the input tensor is transposed to the shape NxDxL and a second multi-head attention learns depth correlation over DxL.
- MSA also use the pre-trained SAM decoder and adds three Adapters. The first one also integrates the prompt information in the low-dimension space.
- The encoder is pretrained on RadImageNet (1.25 CT, MRI and US images), EyePACsp (88k fundus images) and BCN-20000 and HAM-10000 (30k dermoscopic images). They used a combination of MAE, Contrastive Embedding Mixup and Shuffle Embedding Prediction.
- Evaluation on abdominal multi-organ segmentation (AMOS2022 and BTCV), fundus image segmentation (REFUGE and RIGA), brain tumor segmentation (BraTS), thyroid nodule segmentation (TNSCU and DDTI) and melanoma or nevus segmentation (ISIC).
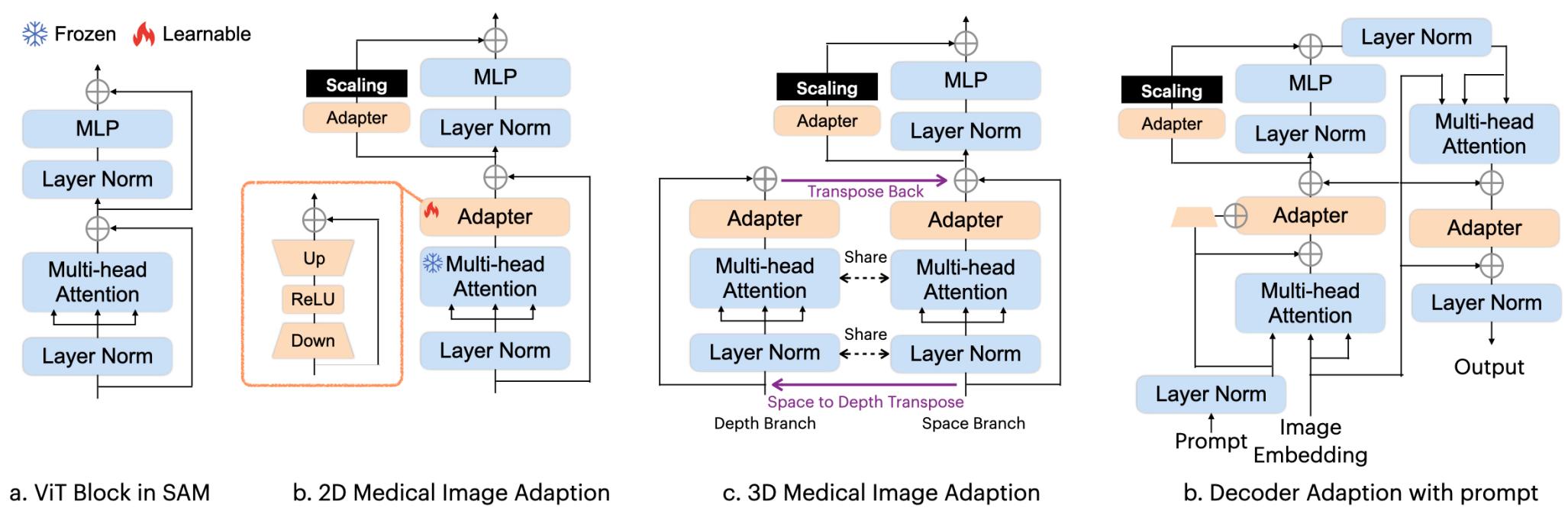
Figure 5. The MSA architecture.
SAMUS: Adapting Segment Anything Model for Clinically-Friendly and Generalizable Ultrasound Image Segmentation
- The prompt encoder and the mask decoder are kept as it is without any adjustment and their parameters are frozen.
- The input spatial size is reduced from 1024x1024 to 256x256 to reduce GPU memory cost.
- The patch embedding has the same parameters as in SAM but half its stride to better process local information from patch boundaries.
- A feature adapter is placed right after patch embedding to account for the size and stride modifications and is combined with a position adapter.
- 4 other feature adapters are placed around the MLP layer of the transformer blocks.
- A lightweight CNN branch composed of four sequentially-connected convolution-pooling blocks is added in parallel to the image encoder to provide complementary local information.
- The CNN features are connected to the transformer encoder via cross-attention where image embeddings are used as queries and CNN features as keys and values. This is done in the four global transformer blocks of the image encoder.
- Model is trained/validated/tested on US30K, a large ultrasonic dataset containing data from seven publicly-available datasets.
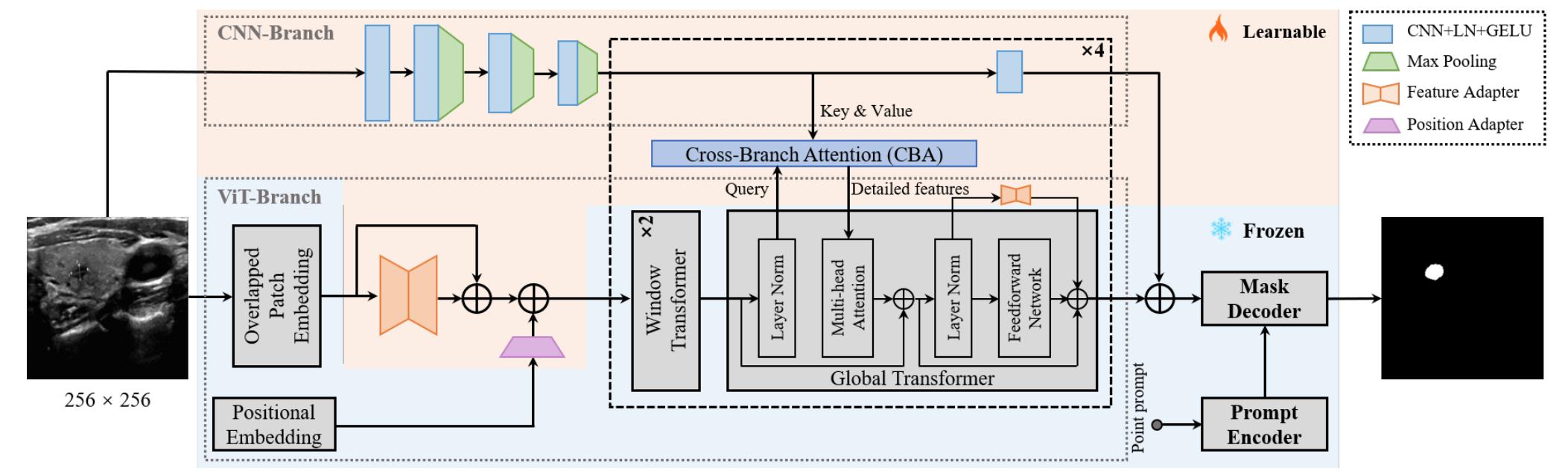
Figure 6. Overview of SAMUS.
Results
As three of these methods were released in very a short space of time, they did not include cross-method comparison. Only SAMUS provide an evaluation of the four models on the same task.
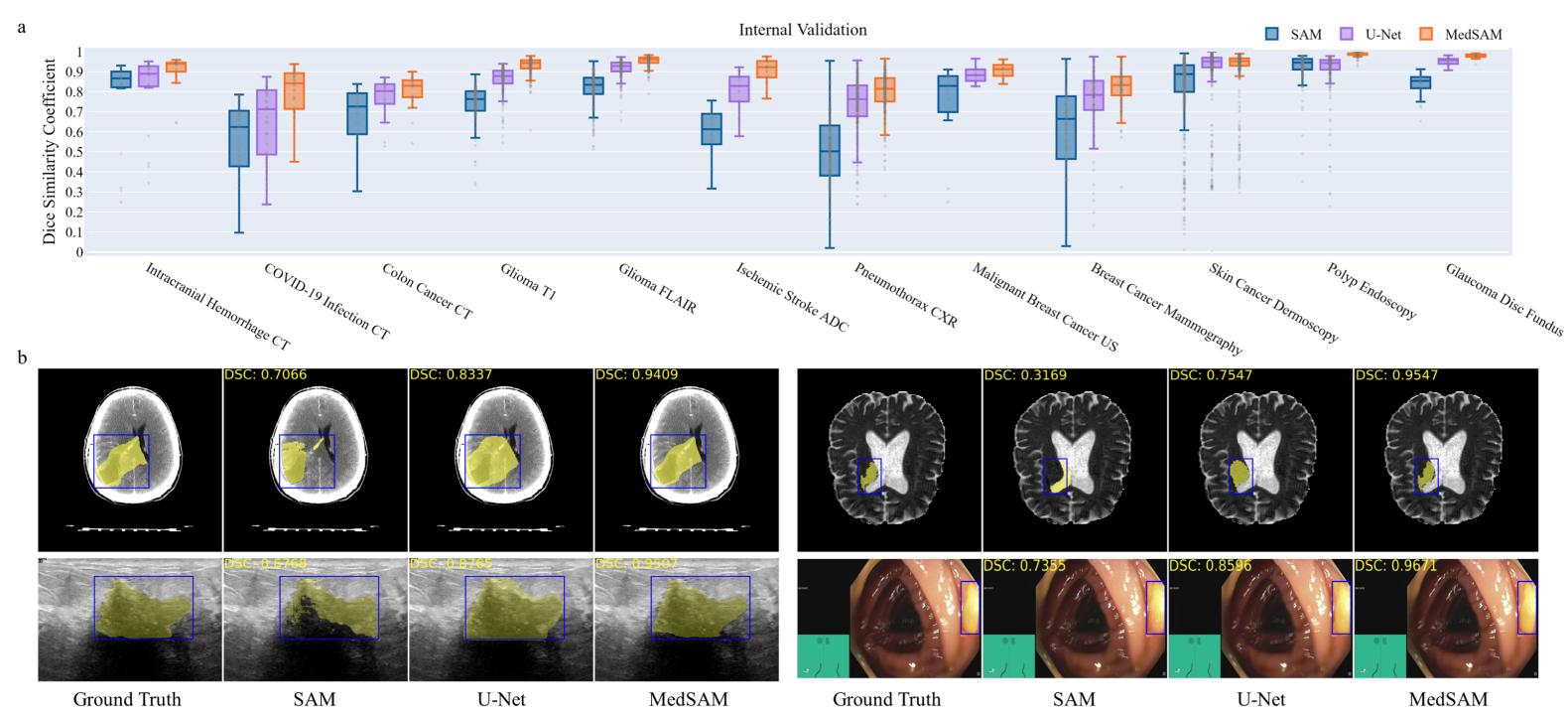
Figure 7. Results of MedSAM on various tasks.
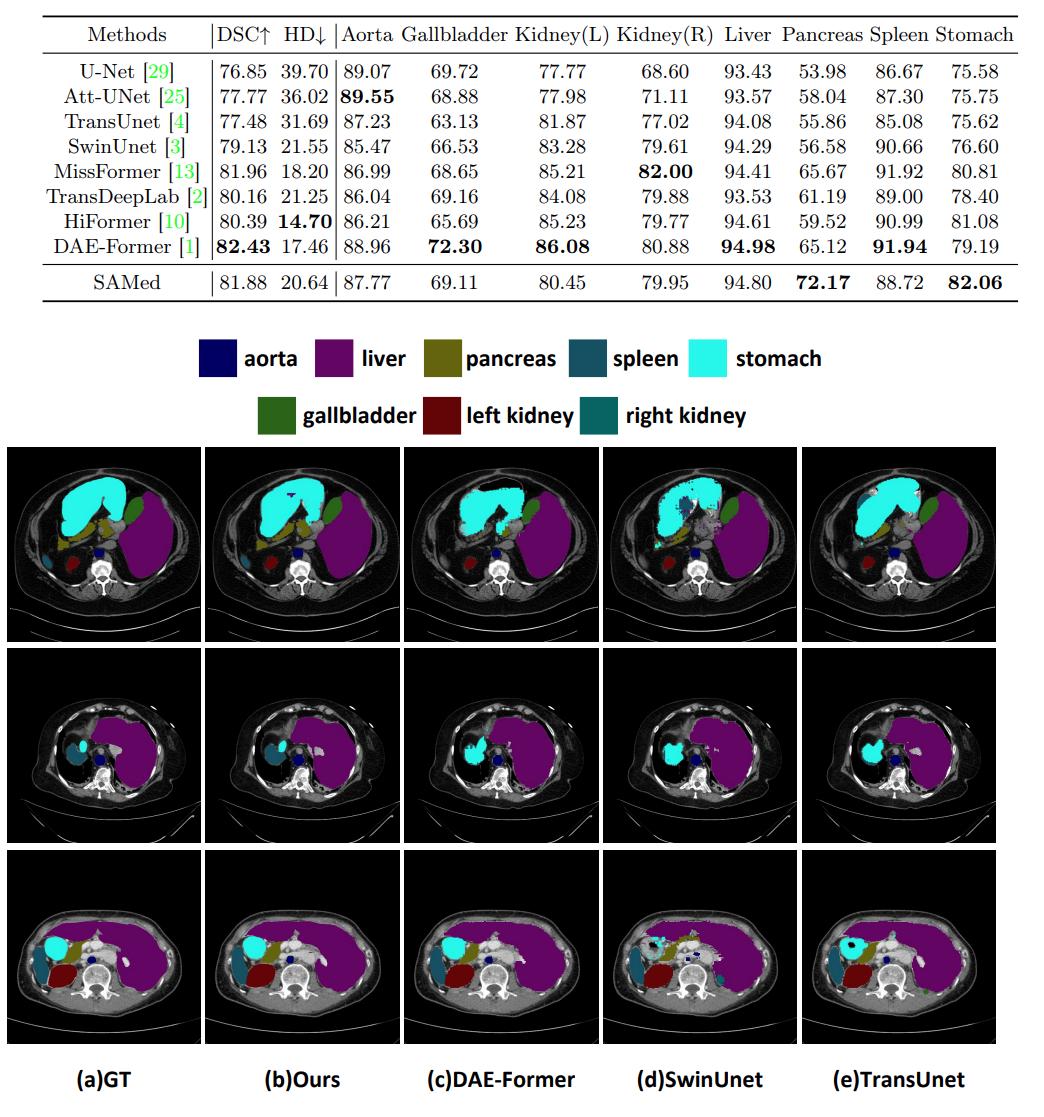
Figure 8. Results of SAMed on the Synapse multi-organ CT segmentation.
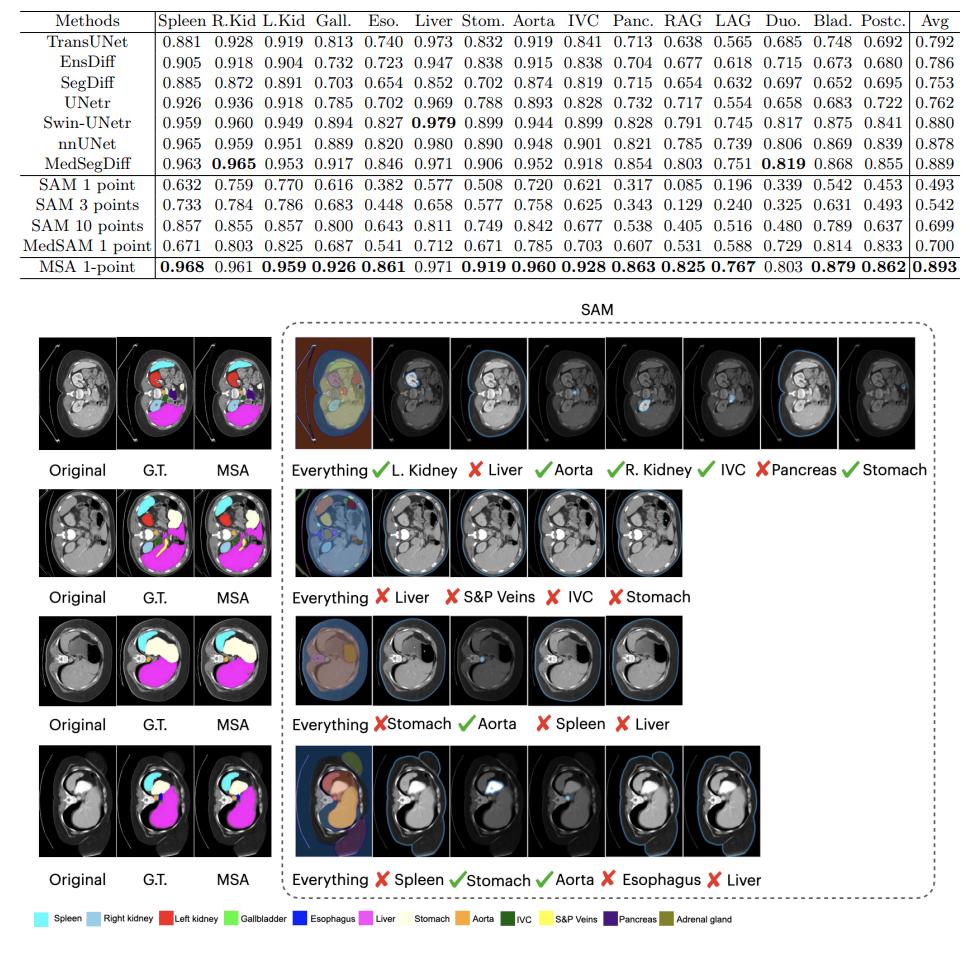
Figure 9. Results of MSA on multi-organ segmentation (AMOS dataset).
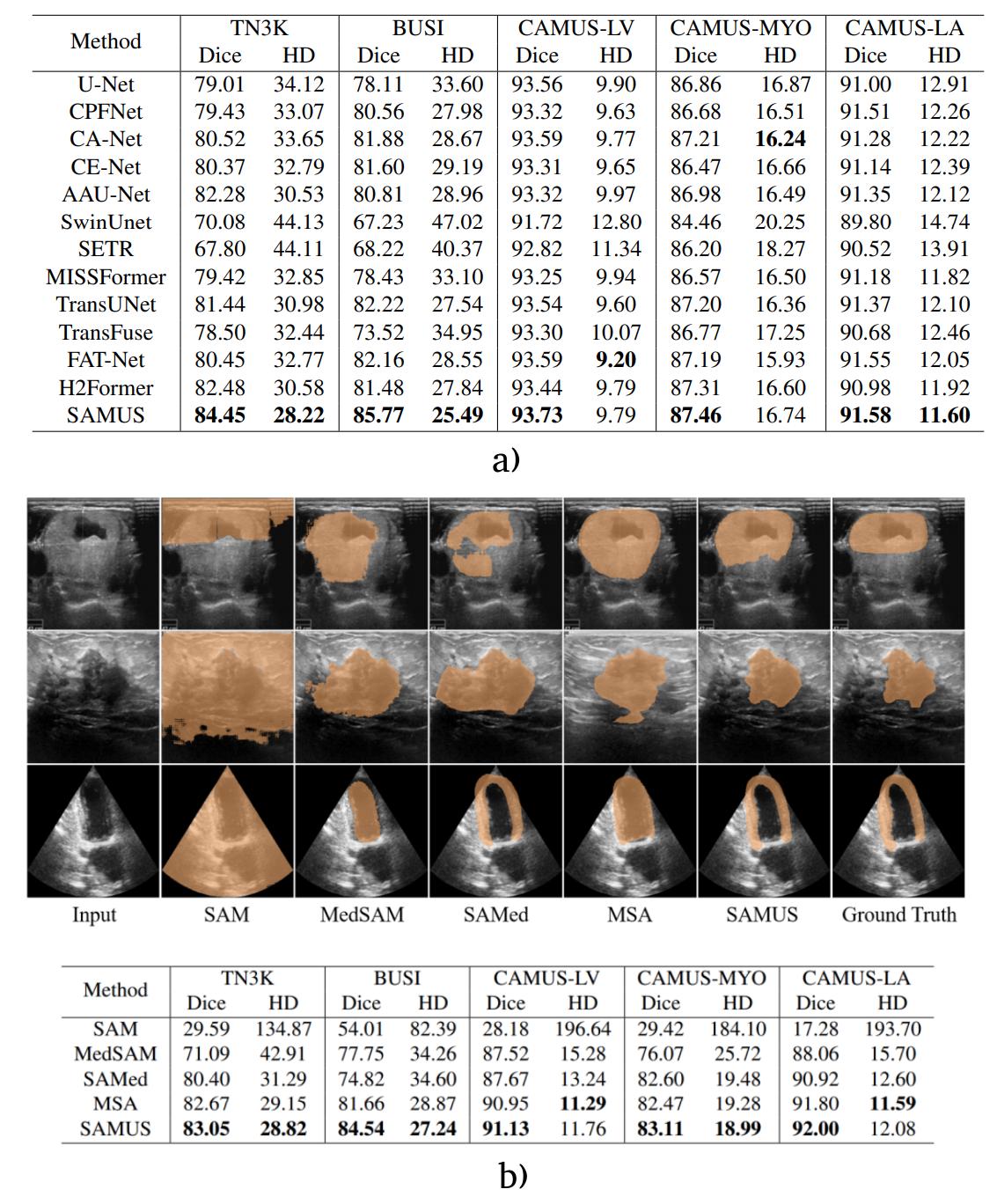
Figure 10. a) Results of SAMUS, comparison with state-of-the-art methods. b) Compirason of SAMUS with other SAM-adapted models.
Finetuning SAM on medical imaging dataset is essential to deal with the domain shift with natural images. However, more advanced strategies, such as using low-rank adapter, seem to work better than finetuning all the model parameters. Adapted SAM reaches performances in-par or superior to fully state-of-the-art supervised models on various tasks.
Latest results shown in SAMUS tend to show that the adaptation strategy could be coupled with external feature extractor, which may also be useful to increase even more the performances of such models.
Other figures and additional results in the articles include ablation studies, results on more datasets as well as quantitative and qualitative results for multiple-point input prompts and/or box prompts.
Conclusion
Several recent works have leveraged SAM architecture and training and tried to modify it in order to improve its capacities on medical imaging tasks. They mainly rely on Low-rank adaptation modules introduced inside the transformer’s architecture of SAM, but new ideas, such as using a CNN as a local features extractor, may lead to even an greater increase in performances in the future.
References
-
A. Kirillov, E. Mintun, N. Ravi,H. Mao, C. Rolland,L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P. Dollar, R. Girshick, Segment Anything, ICCV 2023, link to paper ↩
-
M. A. Mazurowski, H. Dong, H. Gu, J. Yang, N. Konz, Y. Zhang, Segment Anything Model for Medical Image Analysis: an Experimental Study, April 2023, link to paper ↩
-
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, LoRA: Low-Rank Adaptation of Large Language Models, ICLR 2022, link to paper ↩