Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time
Highlights
- A novel method to improve the accuracy of large models finetuned on specific tasks (focusing on classification),
- A very simple and practical idea of averaging weights of multiple finetuned models for a significant gain,
- They approach ensemble-like performance without increasing the inference time,
- The number of experiments they have done is insane,
- They argue that finetuned models can land at different places of the same validation loss basin due to the flatness of the loss landscape near optimas of pretrained models,
- It has been used recently by authors finetuning Vision-Language models (already 500+ citations).
Methodology
- Consider a pre-trained model with parameters \(\theta_0\). The goal is to finetune this model on a task.
- Let a grid of hyperparameters \(\{h_1, ... h_K\}\), with each \(h_k\) defining a learning rate, data augmentations, seed, etc.
-
The common finetuning methodology is to get a set of model \(\theta_{h_k} = FineTune(\theta_0, h_k), \forall k\leq K\) by finetuning the pre-trained model with each configuration \(h_k\), and choose the best one on a validation set.
-
They define a model soup as the parameters averaged model \(\theta_{S_\mathcal{H}} = \sum_{h\in \mathcal{H}}\theta_h\) for a subset of configurations \(\mathcal{H} \subseteq \{h_1, ... h_K\}\).
- They name the Uniform soup the uniform average of all models of the grid \(\theta_{S_{uniform}} = \sum_{k=1}^K\theta_{h_k}\).
-
They define the Greedy soup as the model obtained by incrementally adding models to the soup (i.e. to the parameters aggregate). They sort the models \(\theta_{h}, \forall h\in \{h_1, ... h_K\}\) in decreasing order of validation accuracy. For each model, they try to add it to the soup, and keep it if it improves the validation accuracy of the current soup.
- They defined more advanced but less interesting soups in Appendix.
Experiments
Experimental setup
- Pre-trained models
- CLIP and ALIGN pre-trained contrastive image-text pairs loss,
- VIT-G/14 on JFT-3B (internal image classification Google dataset),
- Transformers for text classification.
- They use the LP-FT finetuning method
- First train a linear head on top of pre-trained models (linear probe LP),
- Then finetune the whole model end-to-end (finetune FT).
- They finetune on ImageNet,
- They test on
- ImageNet (In Domain ID),
- Five “out-of-distribution” (OOD) datasets: ImageNetV2, ImageNet-R, ImageNetSketch, ObjectNet, and ImageNet-A.
- No data leakage, they kept 2% of ImageNet training set for actual validation.
Intuition
They first experiment with pairs of finetuned models from the same pretrained CLIP version.
Error landscape vizualisation
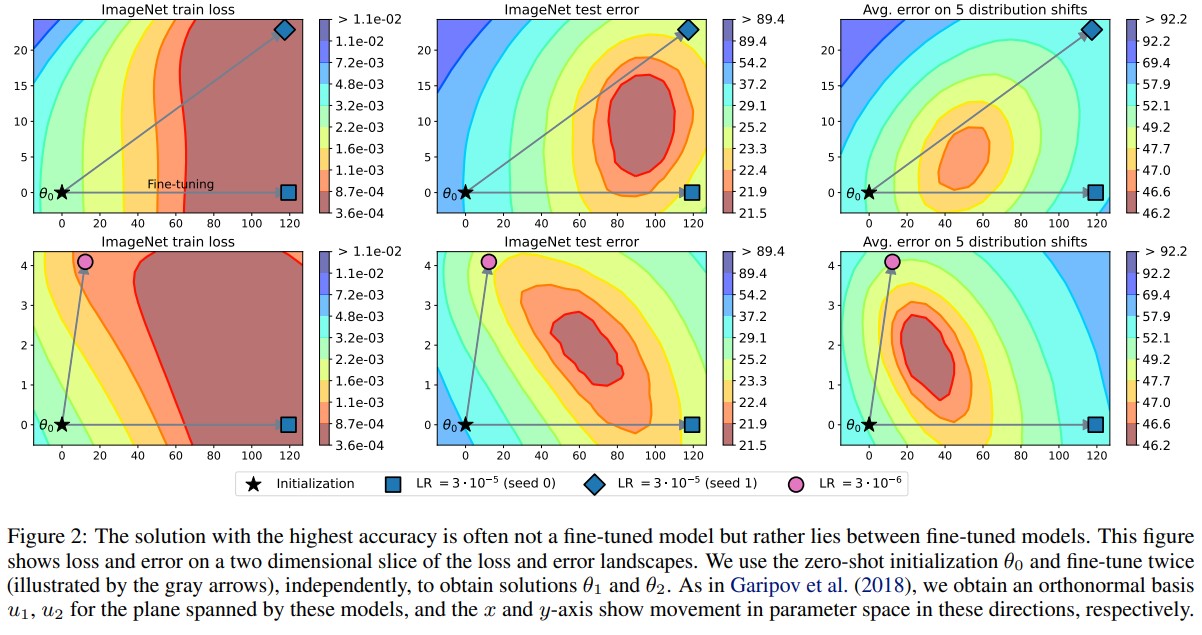
- Finetuned models seem to land on borders of the same validation loss basin with small to medium learning rates. The average has a smaller validation loss.
- They show in Appendix that it is not the case for larger learning rates.
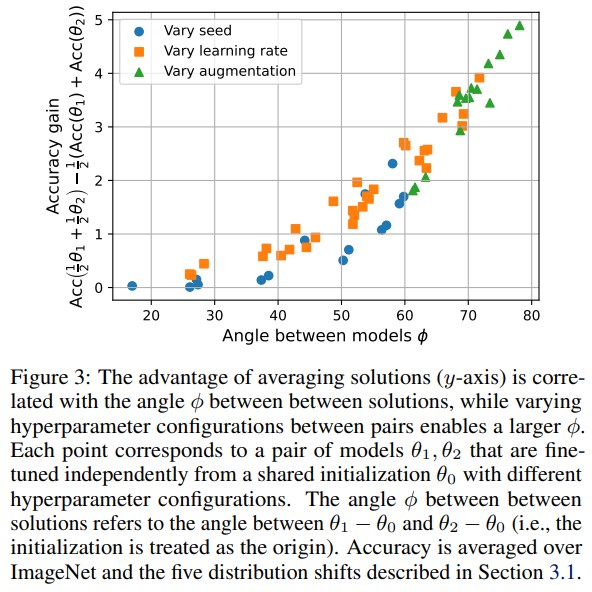
- The more the two finetuned models drift away from each other while staying in the same loss basin, the larger the performance gain by averaging their parameters.
Comparison to ensembles
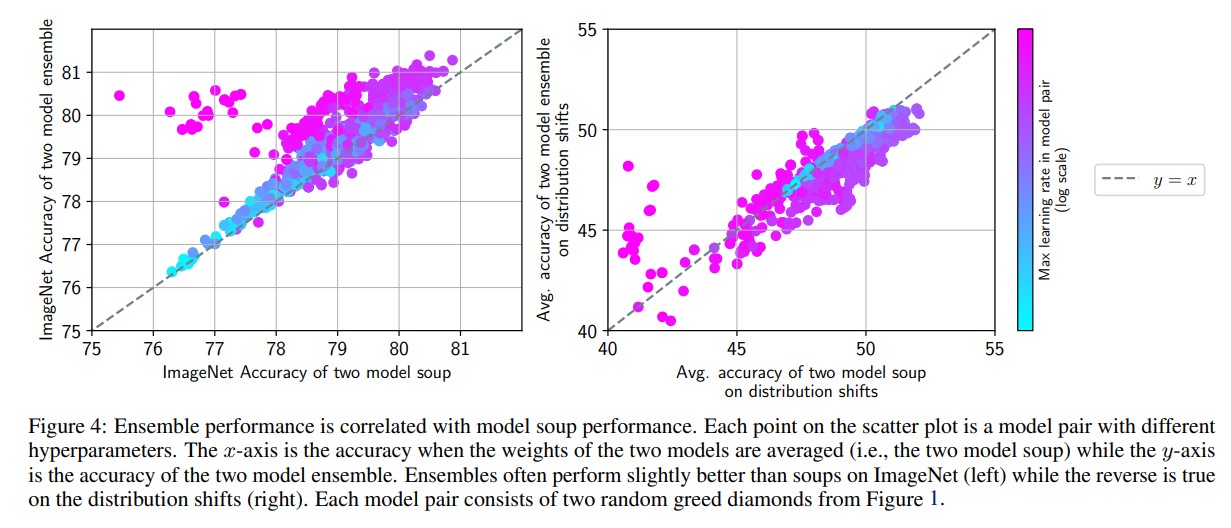
- There is a clear correlation between ensemble and soup performances.
- Ensemble is superior to soup in domain, but soup is superior to ensemble out of domain.
Main results
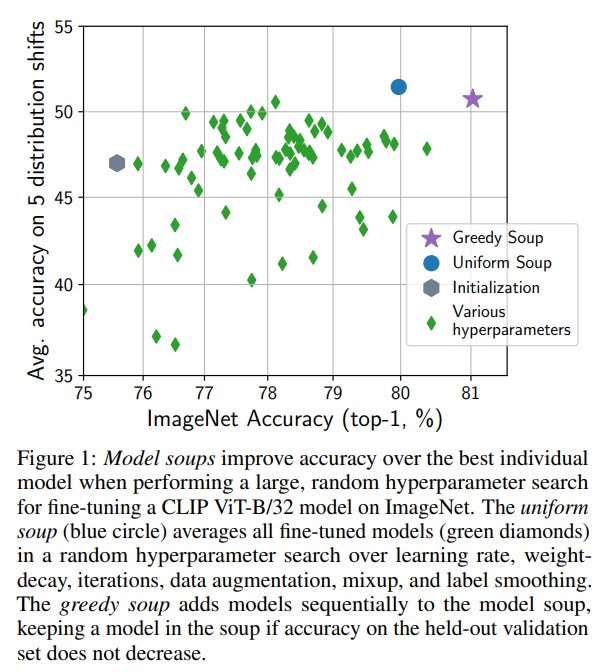
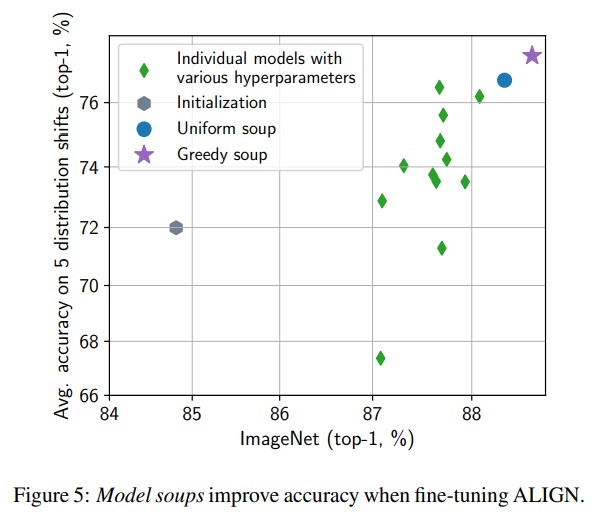
- Soups are better than selecting the best model on a validation set. Greedy soup is clearly better than uniform as it limits the influence of poor hyperparameters choices.
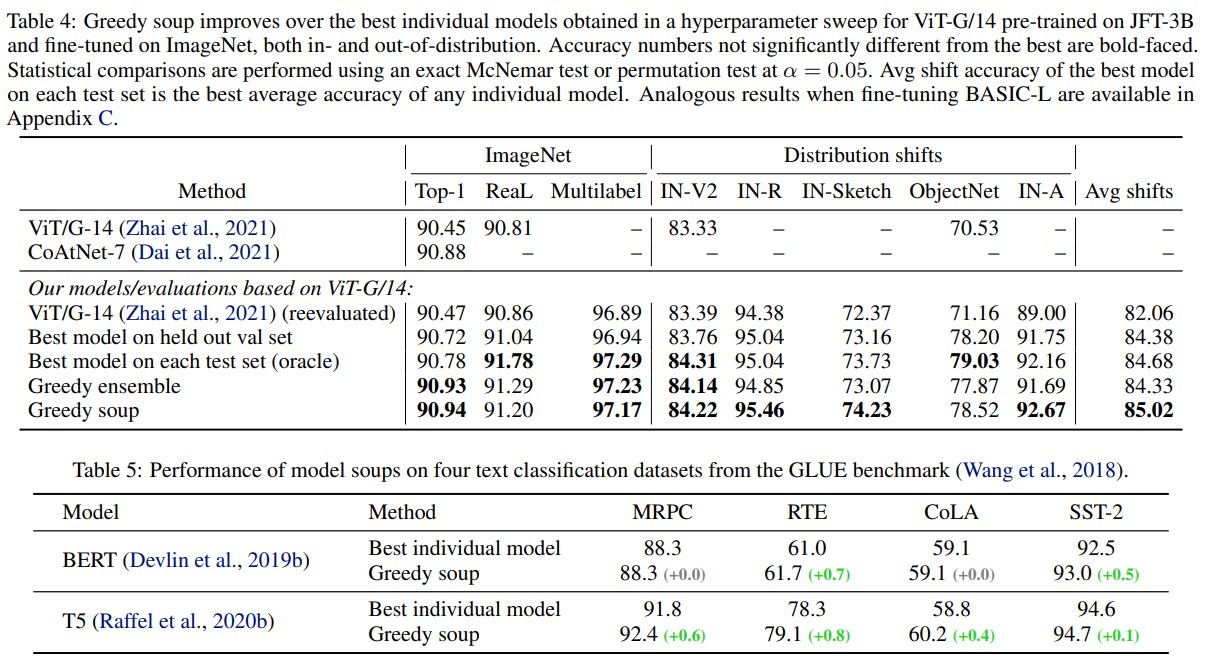
- They were (are?) state-of-the-art on ImageNet for a while.
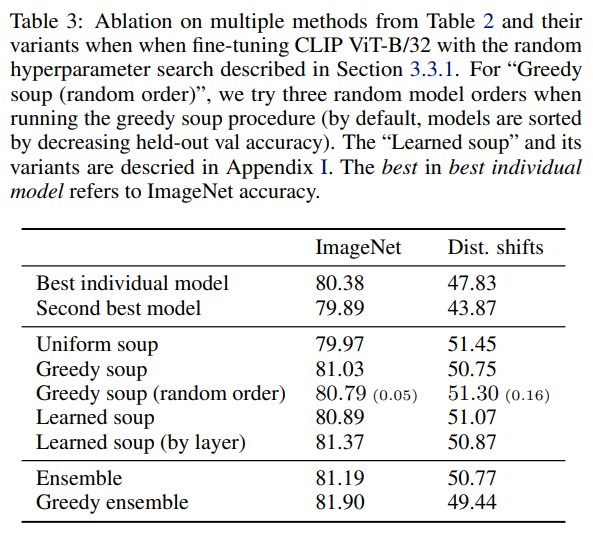
- Ensemble seems to remain better in domain, at the cost of higher inference times.
- Greedy ensembles might be very interesting in practice.
List of additional experiments
- A learned soup;
- Learning the aggregation of models of the soup (too expensive and not interesting).
- Experiments with individual hyperparameters;
- Too many results, see the paper.
- Experiments with the number of models in the soup;
- More models only improve the accuracy of the soups.
- Experiments with large learning rates;
- Finetuned models do not remain in the same loss basin.
- Experiments with smaller models (VIT-B/32) pretrained on a smaller dataset (ImageNet 22k);
- Results are not as convincing, but greedy soup is still better.
- Relation with calibration;
- Soups do not seem to improve calibration while ensembles do.
- Soups of models finetuned on different datasets;
- It does things.
- Relation with Sharpness-Aware Minimization;
- Soups of models trained with and without SAM were better than only SAM or only standard optimization.
- Relation with Exponential Moving Averaging and Stochastic Weight Averaging;
- Soups can be combined with EMA and SWA, even for VIT-B/32 pre-trained on ImageNet 22k.
- Relation with Ensemble distillation;
- Soups are comparable or better.
- Relation with Wise Finetuning (searching for the best linear interpolation between initialization and finetuned model);
- Soups go beyond what Wise-FT can do.
Conclusion
- Intringuigly simple idea of averaging finetuned models for better performance,
- Already kind of popular,
- One cannot say if it is really transposable to regular models pretrained on small datasets finetuned on even smaller datasets, as well as on other tasks (image segmentation, object detection, etc.)