Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Highlights
- Introduce a joint-embedding predictive architecture for images (I-JEPA).
- The goal is to learn highly semantic image representations without the use of hand-crafted view augmentations.
Introduction
Self-supervised learning is a method of representation learning where the model attempts to understand the relationships between its inputs. Currently, there are two main approaches:
- Invariance-based pretraining (DINO1, SimCLR v22) can provide high-level semantic representations but may lead to decreased performance in certain downstream tasks (like segmentation) or with new data distributions.
- Generative pretraining (MAE3,iBOT4, SimMIM5) requires less prior knowledge and offers greater generalizability but results in lower semantic-level representations and underperforms in off-the-shelf evaluations.
Some recent methods are hybrid (MSN6, data2vec7), using mask generation and contrastive loss. However, most of the methods rely on hand-crafted image transformations.
The goal of the authors is to enhance the semantic quality of self-supervised representations while ensuring applicability to a broader range of tasks. I-JEPA does not rely on additional prior knowledge encoded through image transformations, thereby reducing bias.
Methodology
I-JEPA is similar to the generative masked autoencoders (MAE) method, with two main differences:
- I-JEPA is non-generative: it focuses only on predicting the representations of target blocks from context blocks, rather than reconstructing the original data.
- Predictions are made in an abstract representation space (or feature space) rather than directly in the pixel or token space.
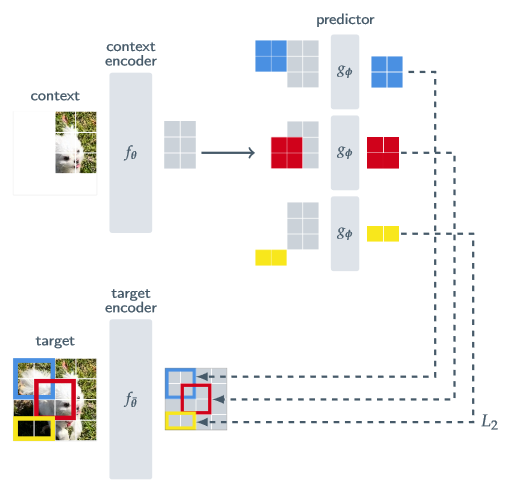
Figure 1. I-JEPA: The Image-based Joint-Embedding Predictive Architecture.
-
Targets: From a sequence of N non-overlapping patches from an input image y, the target-encoder \(f_{\bar{\theta}}\) obtains a corresponding patch-level representation \(s_y = \{s_{y_1} , \dots , s_{y_N} \}\). Randomly sample M (possibly overlapping) blocks from the target representation \(s_y\). \(B_i\) is the mask of the block i and \(s_y(i)=\{s_{y_j}\}_{j \in B_i}\) is its representation. These M representation blocks are masked, they are the target of the model.
-
Context: Sample a single block x from the image y and remove overlapping regions with target blocks. Then use context-encoder \(f_{\theta}\) to get the context representation. \(B_x\) is the mask of the block x and \(s_x=\{s_{x_j}\}_{j \in B_x}\) is its representation.
-
Predictions: For each target \(s_y(i)\), use the output of the context encoder \(s_x\) along with a mask token for each patch of the target. The predictor \(g_{\Phi}\) generates patch-level predictions \(s_{\hat{y}(i)}=\{s_{\hat{y}_j}\}_{j \in B_i}\).
-
Loss: \(\mathcal{L} = \frac{1}{M} \sum_{i=1}^{M} \mathcal{D}(s_{\hat{y}(i)},s_y(i)) = \frac{1}{M} \sum_{i=1}^{M} \sum_{j \in B_i} \lVert s_{\hat{y}(j)} - s_y(j) \lVert_2^2\) The parameters of \(\Phi\) and \(\theta\) are learned through gradient-based optimization while the parameters of \(\bar{\theta}\) are updated using EMA (Exponential Moving Average) of the \(\theta\) parameters.
A Vision Transformer (ViT) architecture is used for the context encoder, target encoder, and predictor.
Results
Image classification
- After self-supervised pretraining, the model weights are frozen and a linear classifier is trained on top using the full ImageNet-1K training set:
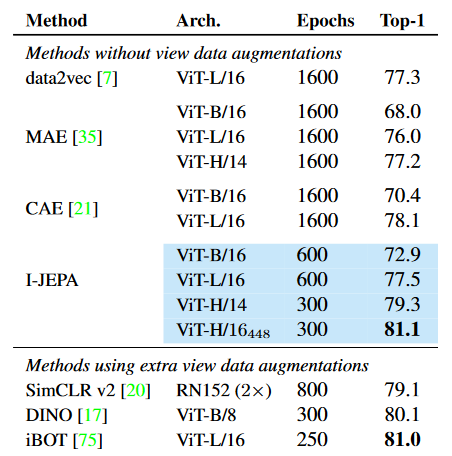
Figure 2. Linear-evaluation on ImageNet-1k (the ViT- H/16 448 is pretrained at a resolution of 448 x 448, the others at 224 x 224).
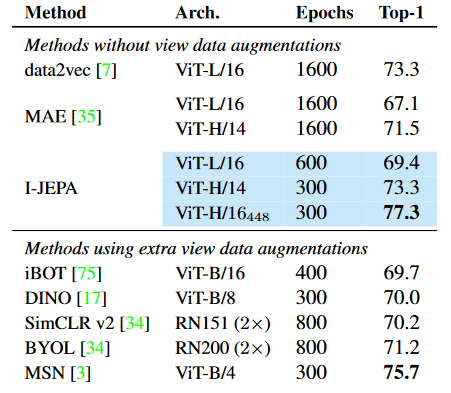
Figure 3. Semi-supervised evaluation on ImageNet-1K using only 1% of the available labels (12 or 13 images per class). Models are adapted via fine-tuning or linear-probing, depending on whichever works best for each respective method. The ViT- H/16 448 is pretrained at a resolution of 448 x 448, the others at 224 x 224.
Figure 4. Linear-evaluation on downstream image classification tasks.
Local prediction tasks
Figure 5. Linear-evaluation on downstream low-level tasks consisting of object counting (Clevr/Count) and depth prediction (Clevr/Dist).
Ablation study

Figure 6. Evaluating impact of pre-training dataset size and model size on transfer tasks.
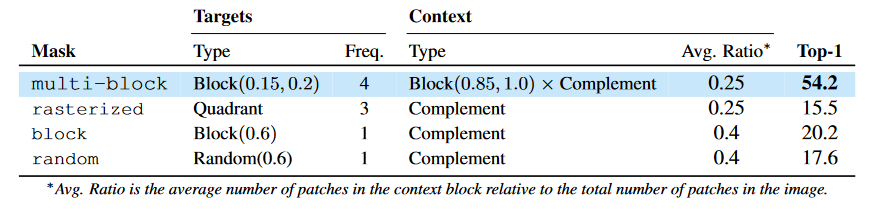
Figure 7. Linear evaluation on ImageNet-1K using only 1% of the available labels after I-JEPA pretraining of a ViT-B/16 for 300 epochs. Comparison of proposed multi-block masking strategy. In "rasterized masking" the image is split into four large quadrants; one quadrant is used as a context to predict the other three quadrants. In "block masking", the target is a single image block and the context is the image complement. In "random masking", the target is a set of random image patches and the context is the image complement.

Figure 8. Linear evaluation on ImageNet-1K using only 1% of the available labels. The semantic level of the I-JEPA representations degrades significantly when the loss is applied in pixel space, rather than representation space.
General performances
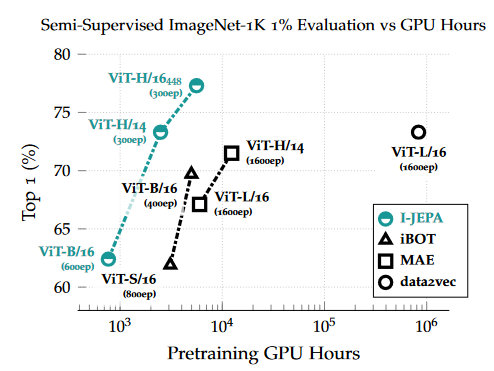
Figure 9. Semi-supervised evaluation on ImageNet-1K 1% as a function of pretraining GPU hours. I-JEPA requires less compute than previous methods to achieve strong performance.

Figure 10. Visualization of I-JEPA predictor representations. For each image: first column contains the original image; second column contains the context image, which is processed by a pretrained I-JEPA ViT-H/14 encoder. Green bounding boxes in subsequent columns contain samples from a generative model. The generative model decodes the output of the predictor, conditioned on positional mask tokens corresponding to the location of the green bounding box.
Conclusions
- In contrast to view-invariance-based methods, I-JEPA learns semantic image representations without relying on hand-crafted data augmentations.
- By predicting in representation space, the model converges faster than pixel reconstruction methods and achieves high-level semantic representations.
References
-
Caron, Mathilde, et al. “Emerging properties in self-supervised vision transformers.” Proceedings of the IEEE/CVF international conference on computer vision. 2021, link to paper ↩
-
Chen, Ting, et al. “Big self-supervised models are strong semi-supervised learners.” Advances in neural information processing systems 33 (2020): 22243-22255, link to paper ↩
-
He, Kaiming, et al. “Masked autoencoders are scalable vision learners.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022, link to paper ↩
-
Zhou, Jinghao, et al. “ibot: Image bert pre-training with online tokenizer.” arXiv preprint arXiv:2111.07832 (2021). link to paper ↩
-
Xie, Zhenda, et al. “Simmim: A simple framework for masked image modeling.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022, link to paper ↩
-
Assran, Mahmoud, et al. “Masked siamese networks for label-efficient learning.” European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022, link to paper ↩
-
Baevski, Alexei, et al. “Data2vec: A general framework for self-supervised learning in speech, vision and language.” International Conference on Machine Learning. PMLR, 2022, link to paper ↩