Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Highlights
- Visual capabilities in recent MultiModal LLMs (MLLMs) still exhibit systematic shortcomings.
- They identify CLIP-blind pairs and construct the Multimodal Visual Patterns (MMVP) benchmark.
- MLLMs have difficulty answering simple questions about nine visual patterns.
- These errors stem mainly from the pre-trained vision encoder and scaling alone may not be the solution.
- They propose a Mixture-of-Features (MoF) approach that can reduce these visual limitations.
Introduction : Is vision good enough for language?
Multimodal Large Language Models (MLLMs) integrate images into LLMs and show remarkable capabilities in tasks such as image understanding and visual question answering.
However they still exhibit visual shortcomings, some of which are surprisingly elementary and evident (Figure 1).
Where do these problems originate? Is it a deficiency in visual modality, language understanding, or their alignment?
A natural hypothesis is that any limitation in the pretrained vision models can cascade into the downstream MLLMs that use them.

Figure 1. MLLMs (here GPT-4V) struggle with seemingly simple questions due to inaccurate visual grounding. red is an incorrect response, green is an hallucinated explanation.
Identifying failure examples
They exploit the erroneous agreements in the embedding space. If two visually different images are encoded similarly by CLIP, then at least one of the images is likely ambiguously encoded. They call such a pair of images a CLIP-blind pair.
They use the corpus datasets, ImageNet and LAIONAesthetics, to collect these CLIP-blind pairs. For each pair, they compute the embeddings using CLIP-ViT-L-14 and DINOv2-ViT-L-14. They return pairs such that the cosine similarity exceeds 0.95 for CLIP embeddings and less than 0.6 for DINOv2 embeddings.
Using these CLIP-blind pairs they build the Multimodal Visual Patterns (MMVP) benchmark.

Figure 2. Constructing MMVP benchmark via CLIP-blind pairs.
Multimodal Visual Patterns (MMVP) benchmark
For each CLIP-blind pair of images, they manually pinpoint the visual details that the CLIP vision encoder overlooks and craft questions that probe these visual details, for example “Is the dog facing left or right?”. The benchmark is made of 150 pairs with 300 questions.
Human performance is evaluated through a user study where users are presented with 300 questions in a randomized sequence.
They consider a pair of images to be correctly answered if both the questions associated with the pair are answered accurately.
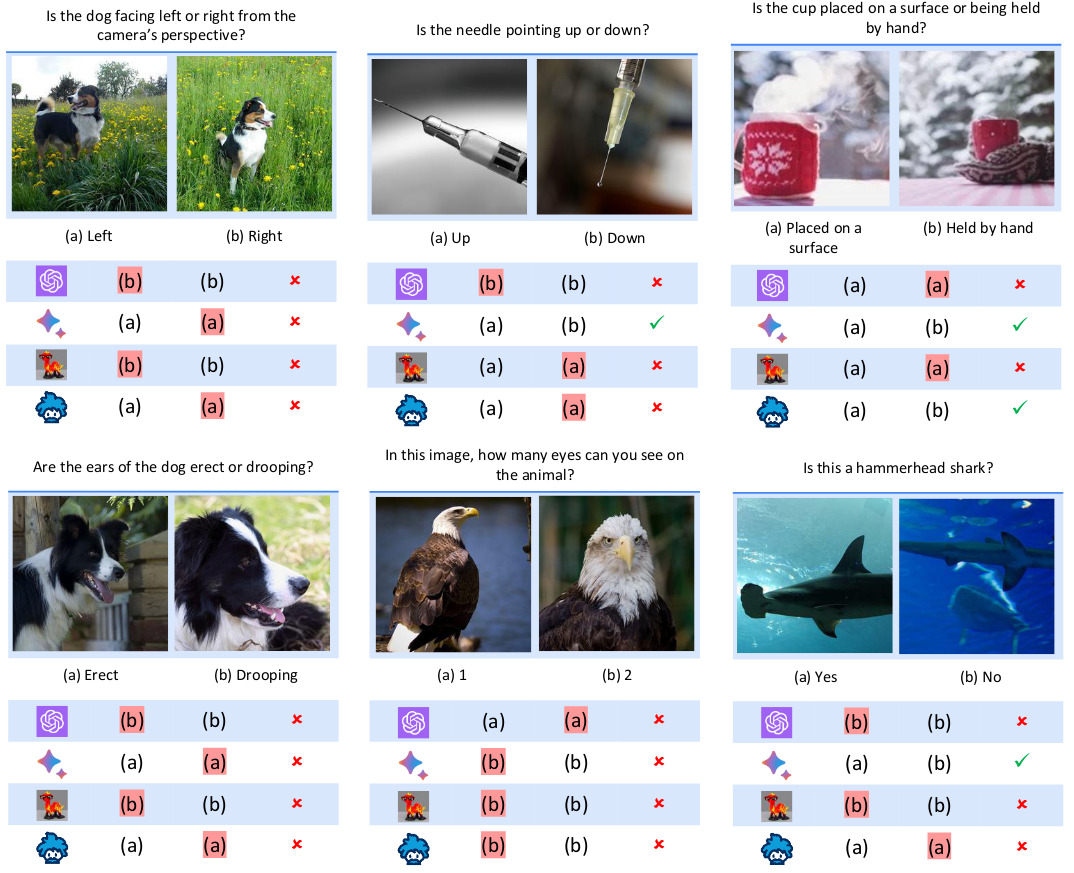
Figure 3. Examples of Questions in the MMVP benchmark.
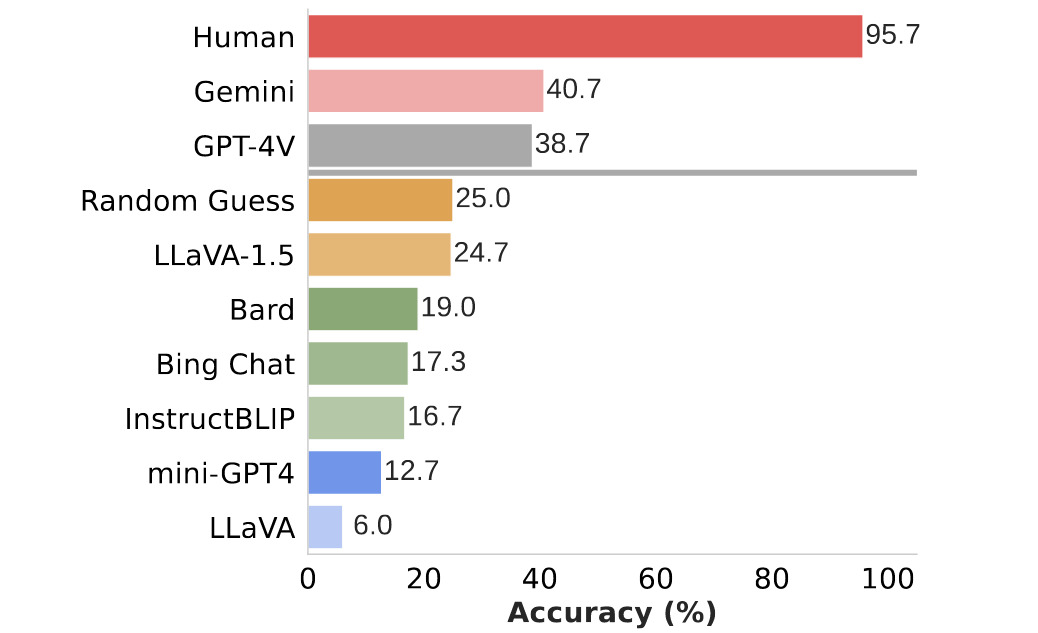
Figure 4. Benchmark results of current SOTA MLLM models and humans.
Systematic Failures in CLIP
They study the systematic visual patterns in MMVP for which CLIP models struggle.
They categorize questions of the MMVP benchmark into 9 categories (see Figure 5) and create a new benchmark to evaluates CLIP models directly (without MLLMs): questions are converted into simpler language descriptions.
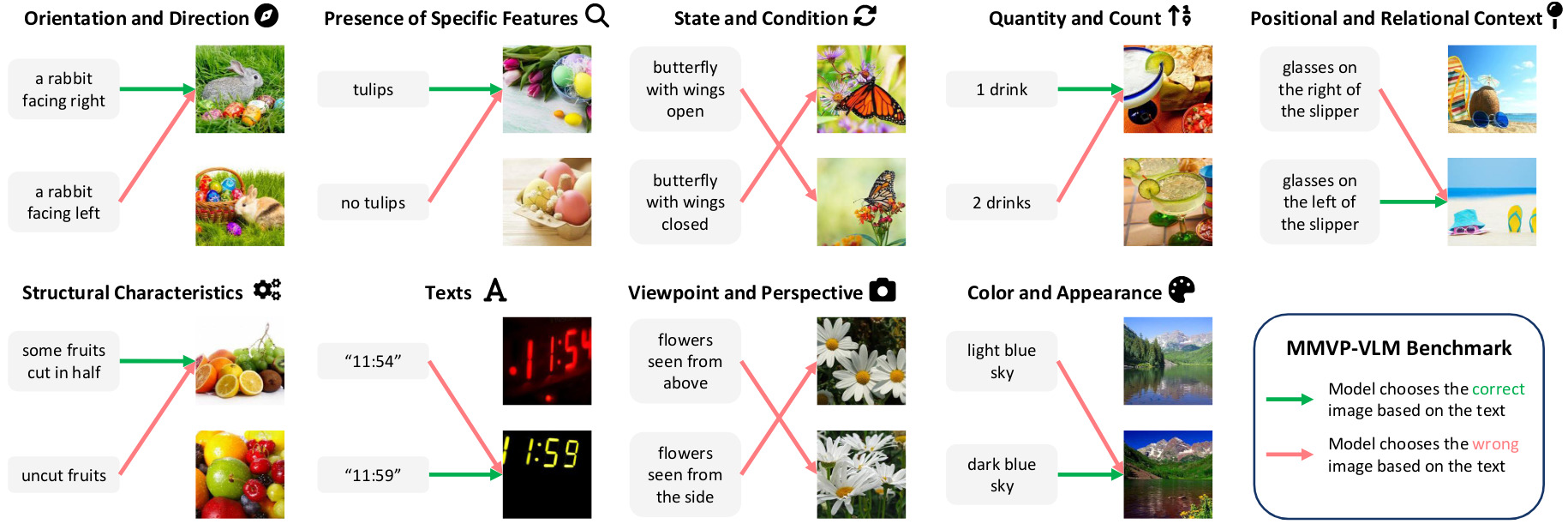
Figure 5. Examples from MMVP-VLM.
Does scaling up solve the problem?
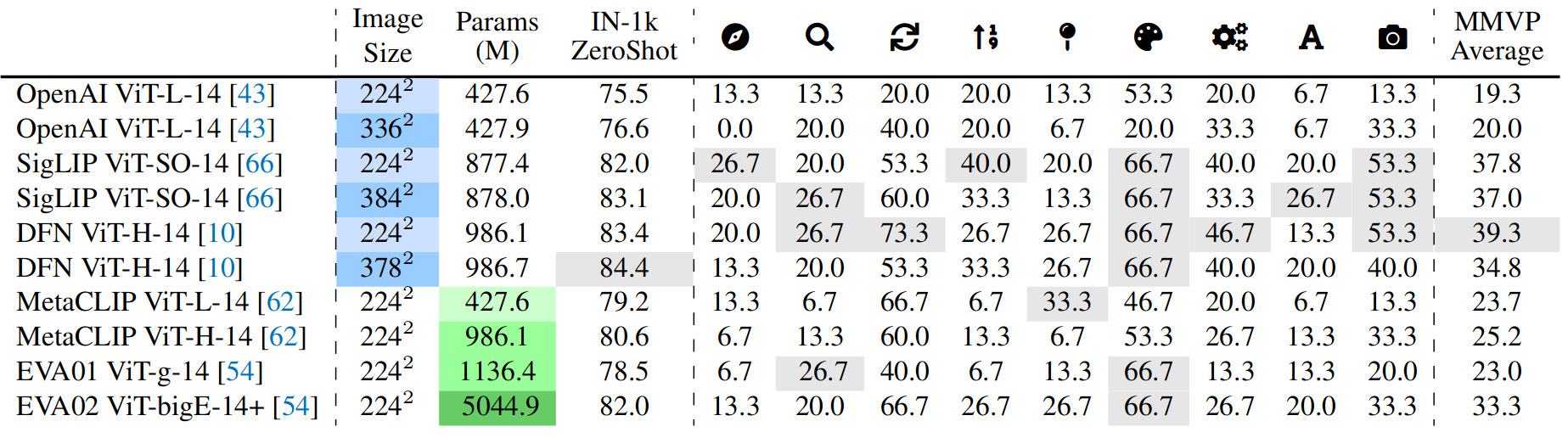
Table 1. Performance of various CLIP based models. Blue is for scaling the input size and green for scaling up the number of parameters.
Increasing model size and training data only aids in identifying two visual patterns – “color and appearance” and “state and condition”.
ImageNet-1k zero-shot accuracy doesn’t reflect model performances for visual patterns.
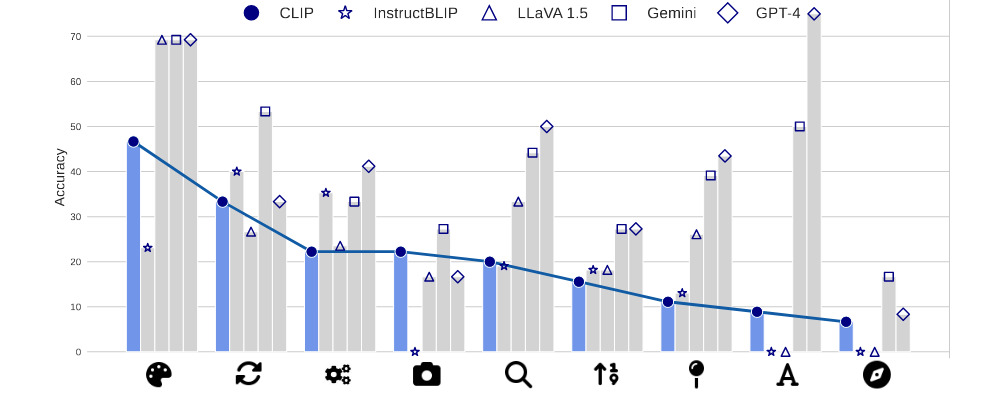
Figure 6. CLIP and MLLM’s performance on visual patterns are correlated. LLaVA 1.5 and InstructBLIP (that explicitly use CLIP) have a correlation score greater than 0.7.
Mixture-of-Features (MoF) for MLLM
If MLLM’s visual shortcomings come from the CLIP vision encoder, how to build a better one?
They try to mix CLIP features with features coming from a visual-only self-supervised model (like DINO) which have better visual grounding.
For their experiments, they use the open-souce model LLaVA and DINOv2 for the SSL model.
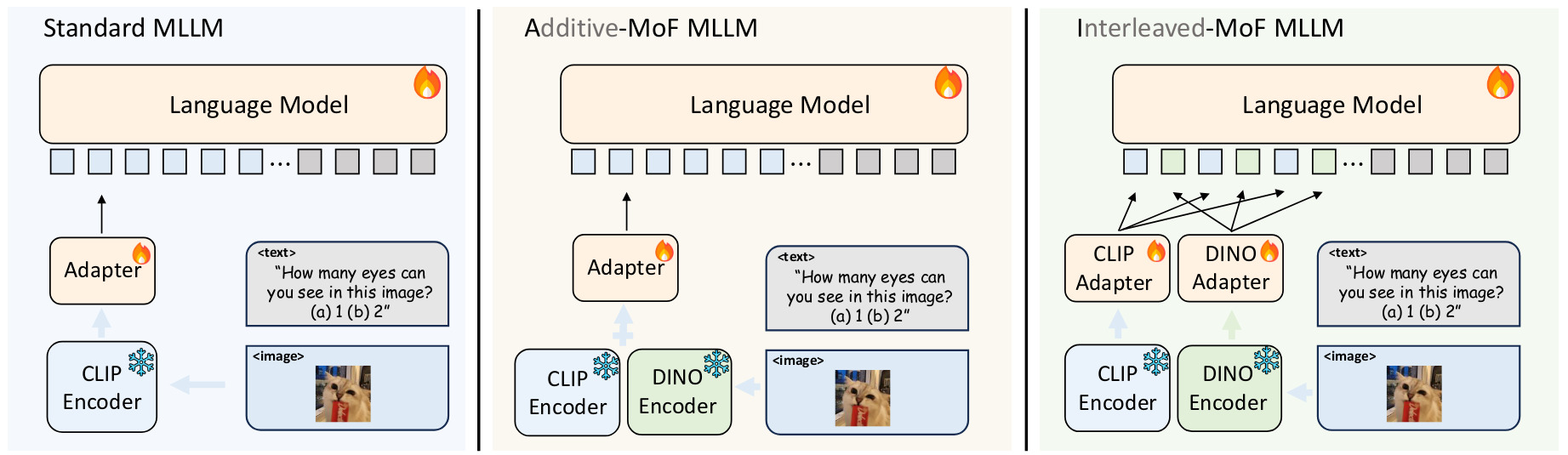
Figure 7. Different Mixture-of-Feature (MoF) Strategies in MLLM.
Additive MoF
\[F_{A-MoF} = \alpha*F_{DINOv2} + (1-\alpha)*F_{CLIP}\]They evaluate the model’s visual grounding ability with MMVP and instruction-following capability with the LLaVA benchmark.
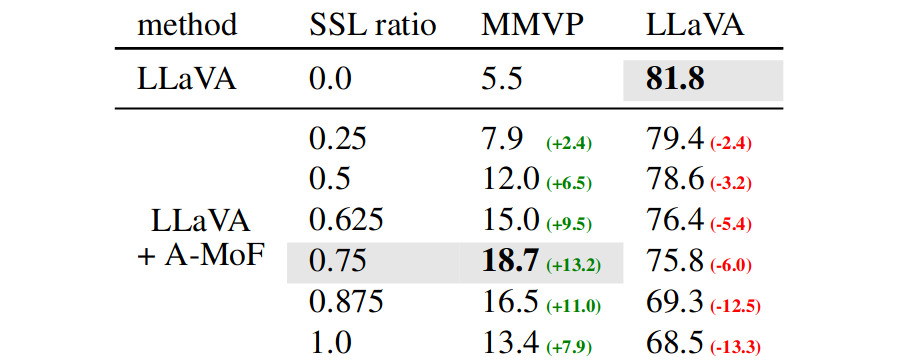
Table 2. Empirical Results of Additive MoF.
There is a trade-off, increasing \(\alpha\) improve visual grounding abilities but reduces instruction-following capability.
Interleaved MoF
They try another method in which features of CLIP and DINOv2 are interleaved while maintaining their spatial order.
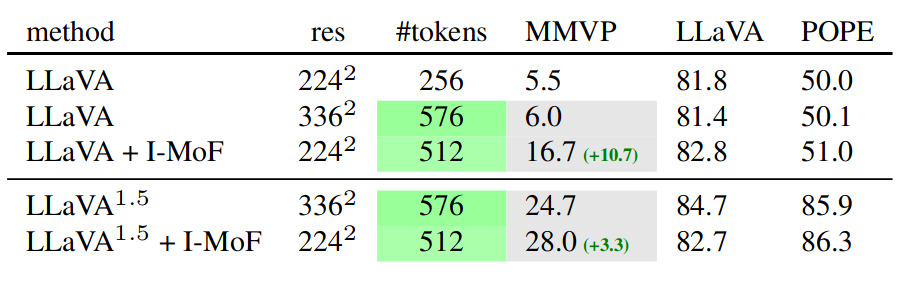
Table 3. Empirical Results of Interleaved MoF.
It increases visual grounding abilities without compromising the ability to follow instructions.
To go further
Pooyan Rahmanzadehgervi, Logan Bolton, Mohammad Reza Taesiri, Anh Totti Nguyen (2024) Vision language models are blind. arXiv preprint arXiv:2407.06581 [blog]